Attaching package: 'reshape2'
The following object is masked from 'package:tidyr':
smiths
library(plotly)
Attaching package: 'plotly'
The following object is masked from 'package:ggplot2':
last_plot
The following object is masked from 'package:stats':
filter
The following object is masked from 'package:graphics':
layout
Attaching package: 'MASS'
The following object is masked from 'package:patchwork':
area
The following object is masked from 'package:plotly':
select
The following object is masked from 'package:dplyr':
select
library(lattice)
Attaching package: 'lattice'
The following object is masked from 'package:boot':
melanoma
library(esquisse)library(testthat)
Attaching package: 'testthat'
The following object is masked from 'package:khroma':
compare
The following object is masked from 'package:dplyr':
matches
The following object is masked from 'package:purrr':
is_null
The following objects are masked from 'package:readr':
edition_get, local_edition
The following object is masked from 'package:tidyr':
matches
library(rsconnect)
Attaching package: 'rsconnect'
The following object is masked from 'package:shiny':
serverInfo
Registered S3 method overwritten by 'quantmod':
method from
as.zoo.data.frame zoo
library(rpart)library(RSEIS)
Attaching package: 'RSEIS'
The following object is masked from 'package:boot':
envelope
library(FactoMineR)library(gtsummary)
Attaching package: 'gtsummary'
The following object is masked from 'package:testthat':
matches
The following object is masked from 'package:MASS':
select
library(corrplot)
corrplot 0.92 loaded
library(devtools)
Loading required package: usethis
Attaching package: 'devtools'
The following object is masked from 'package:rsconnect':
lint
The following object is masked from 'package:testthat':
test_file
library(factoextra)
Welcome! Want to learn more? See two factoextra-related books at https://goo.gl/ve3WBa
library(corrr)library(clusterSim)
Loading required package: cluster
library(DataExplorer)library(caret)
Attaching package: 'caret'
The following objects are masked from 'package:DescTools':
MAE, RMSE
The following object is masked from 'package:purrr':
lift
library(rattle)
Loading required package: bitops
Attaching package: 'bitops'
The following object is masked from 'package:DescTools':
%^%
Rattle: A free graphical interface for data science with R.
Version 5.5.1 Copyright (c) 2006-2021 Togaware Pty Ltd.
Type 'rattle()' to shake, rattle, and roll your data.
library(randomForest)
randomForest 4.7-1.2
Type rfNews() to see new features/changes/bug fixes.
Attaching package: 'randomForest'
The following object is masked from 'package:rattle':
importance
The following object is masked from 'package:dplyr':
combine
The following object is masked from 'package:ggplot2':
margin
library(e1071)library(pROC)
Type 'citation("pROC")' for a citation.
Attaching package: 'pROC'
The following objects are masked from 'package:stats':
cov, smooth, var
library(ggpubr) library(psych)
Attaching package: 'psych'
The following object is masked from 'package:randomForest':
outlier
The following objects are masked from 'package:DescTools':
AUC, ICC, SD
The following object is masked from 'package:testthat':
describe
The following object is masked from 'package:boot':
logit
The following objects are masked from 'package:ggplot2':
%+%, alpha
library(knitr)library(gridExtra)
Attaching package: 'gridExtra'
The following object is masked from 'package:randomForest':
combine
The following object is masked from 'package:dplyr':
combine
Notre jeu de donnée APH se composent de 146 observations représentant les 146 hommes répondant à l’étude. Il est inclu 7 variables. Dans le cadre de l’ACP, seul les valeurs quantitatives seront utilisés, pour la suite du traitement on utilisera (d) comme l’ensemble des valeurs quantitatives.
d=APH[,c(1,3,4,5,6,7)]
1. Traitement des valeurs manquantes
nrow(d[!complete.cases(d),])
[1] 22
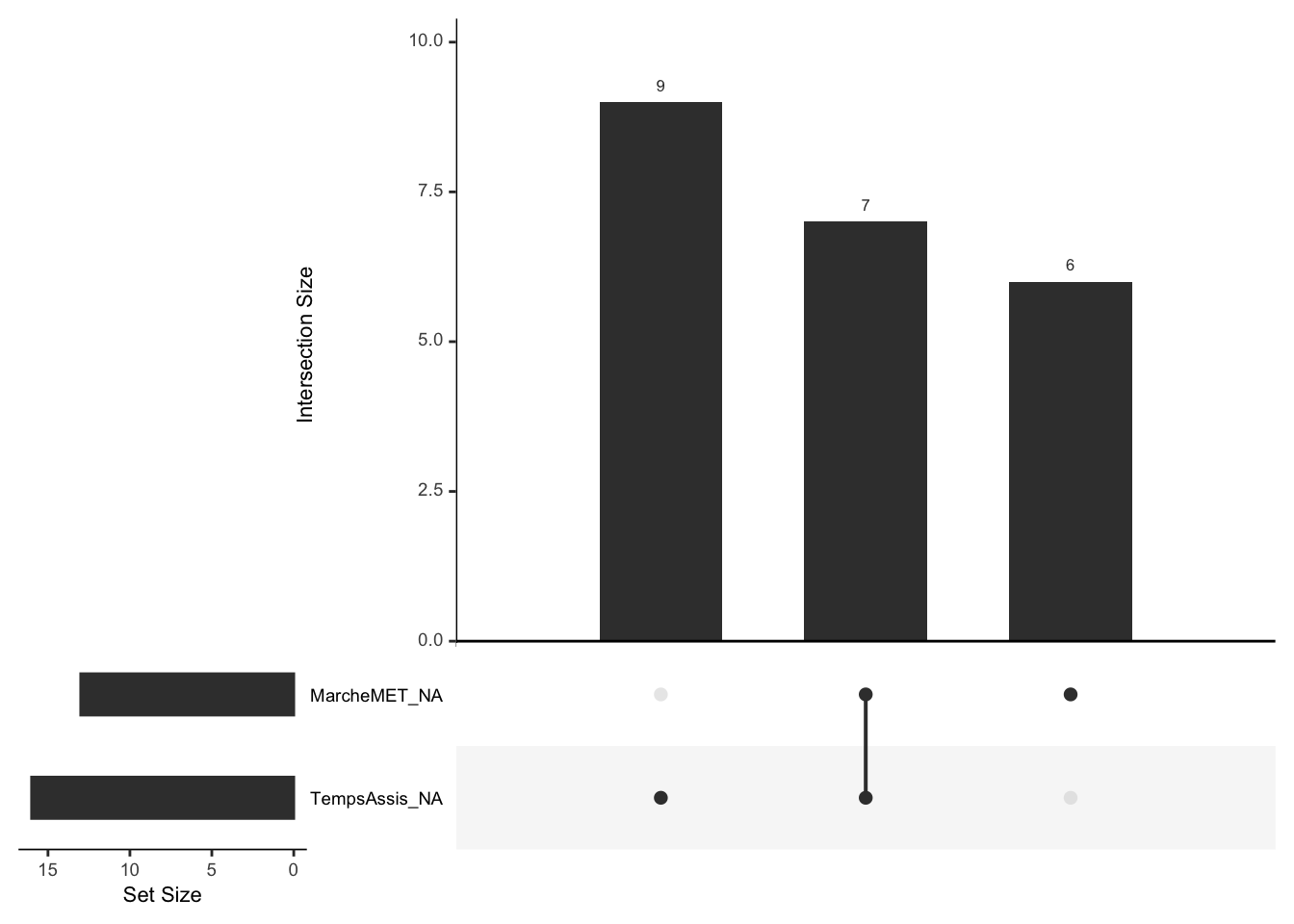
Sur les 146 questionnaires, l’ensemble des données liées à l’activité physique a été rempli. Pour le temps assis, 11 % des valeurs sont manquantes, et 9 % pour la marche, ce qui représente au total 22 valeurs manquantes. Plus précisément, on peut remarquer que 7 des valeurs manquantes sont attribuées à la fois pour le temps assis et pour la marche. Étant donné le faible nombre d’observations disponibles, on ne peut se permettre de supprimer 22 valeurs.
Imputation de données manquantes par les K plus proches voisins
Au vu du faible nombre de donnée, un K trop élevé peut inclure des voisins trop éloignés et diluer la précision de la prédiction. La moyenne pondéré est attribuée à la valeur manquante
d1 <-knnImputation(d, k =7, scale =TRUE, meth ="weighAvg")
2. Traitement des valeurs aberrantes et extrêmes
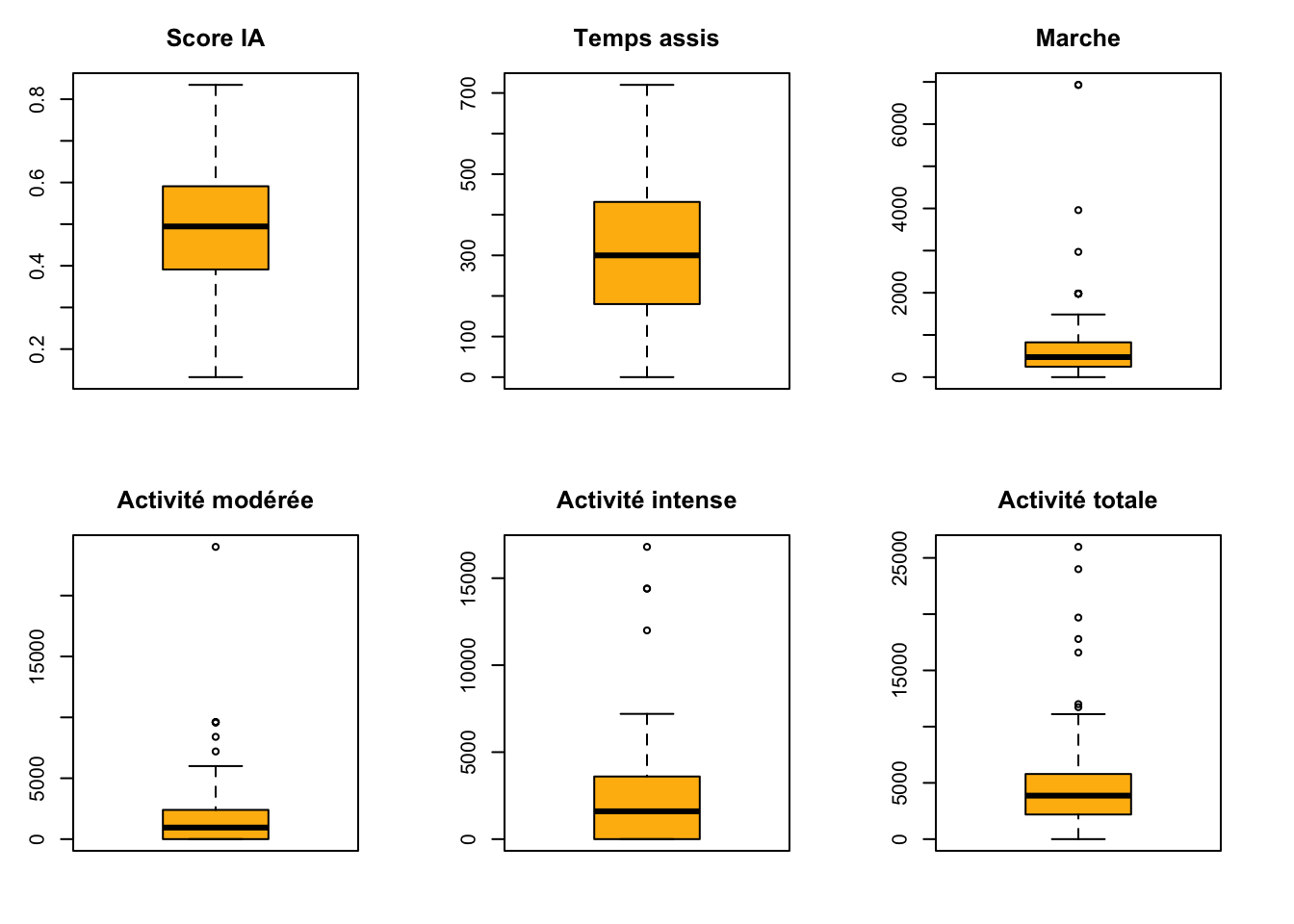
Une valeurs aberrantes, ou extrême, est une observation distante des autres sur un phénomène semblable. L’argument d’une données issus d’une déclaration est suffisant pour imputer ces valeurs.
Des valeurs extrêmes sont visualisées dans l’ensemble des données liées à l’activité physique ainsi que sur les données de marche.
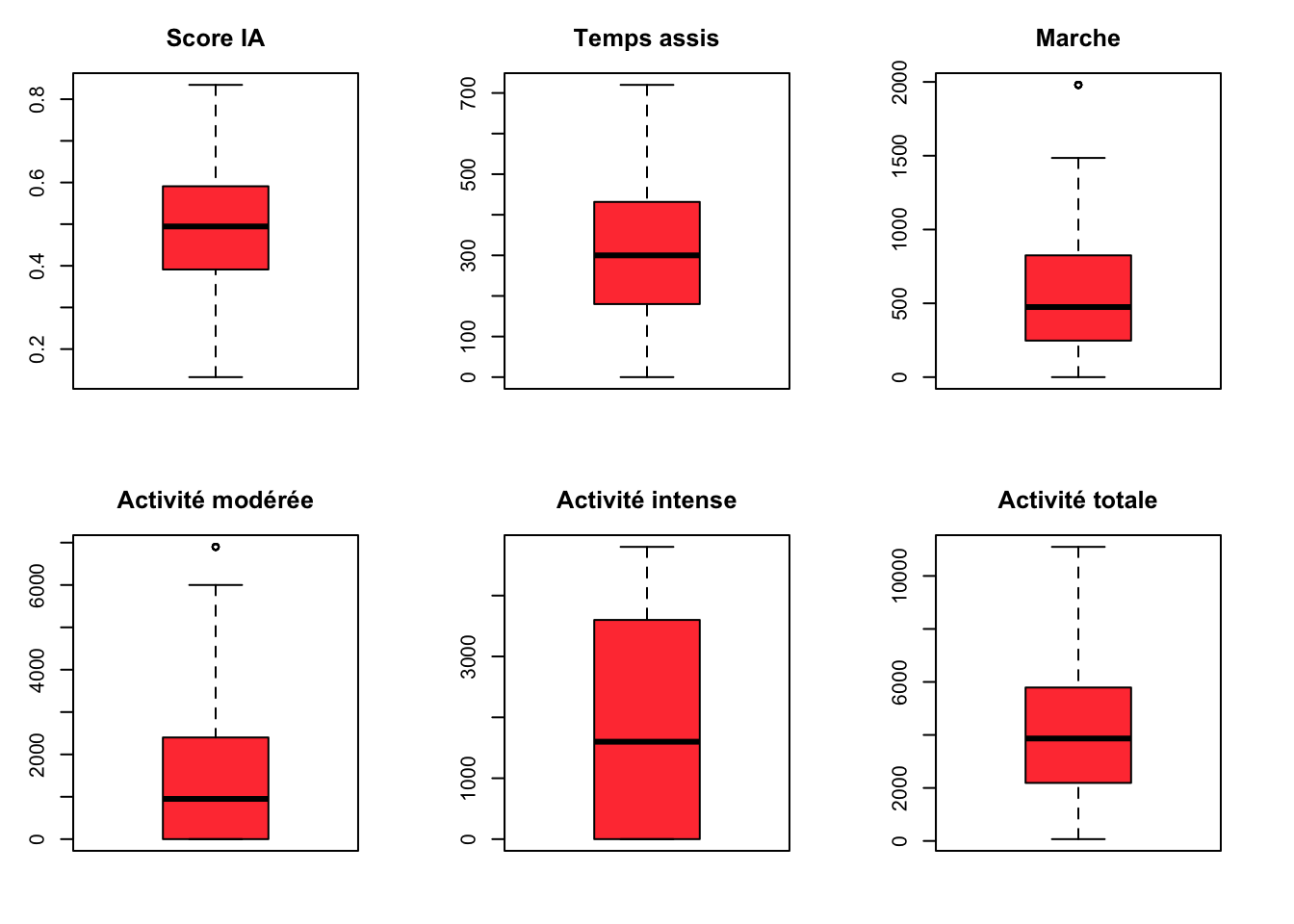
Technique d’imputation de données abérrantes par winzorisation
Pour éviter de supprimer les valeurs, on utilise la technique de winzorisation pour ramener les valeurs dans les limites des boîtes à moustache.
Hypothèse H0 : les données d’activitées physiques et le score suivent une distribution de loi normale
Voir le code
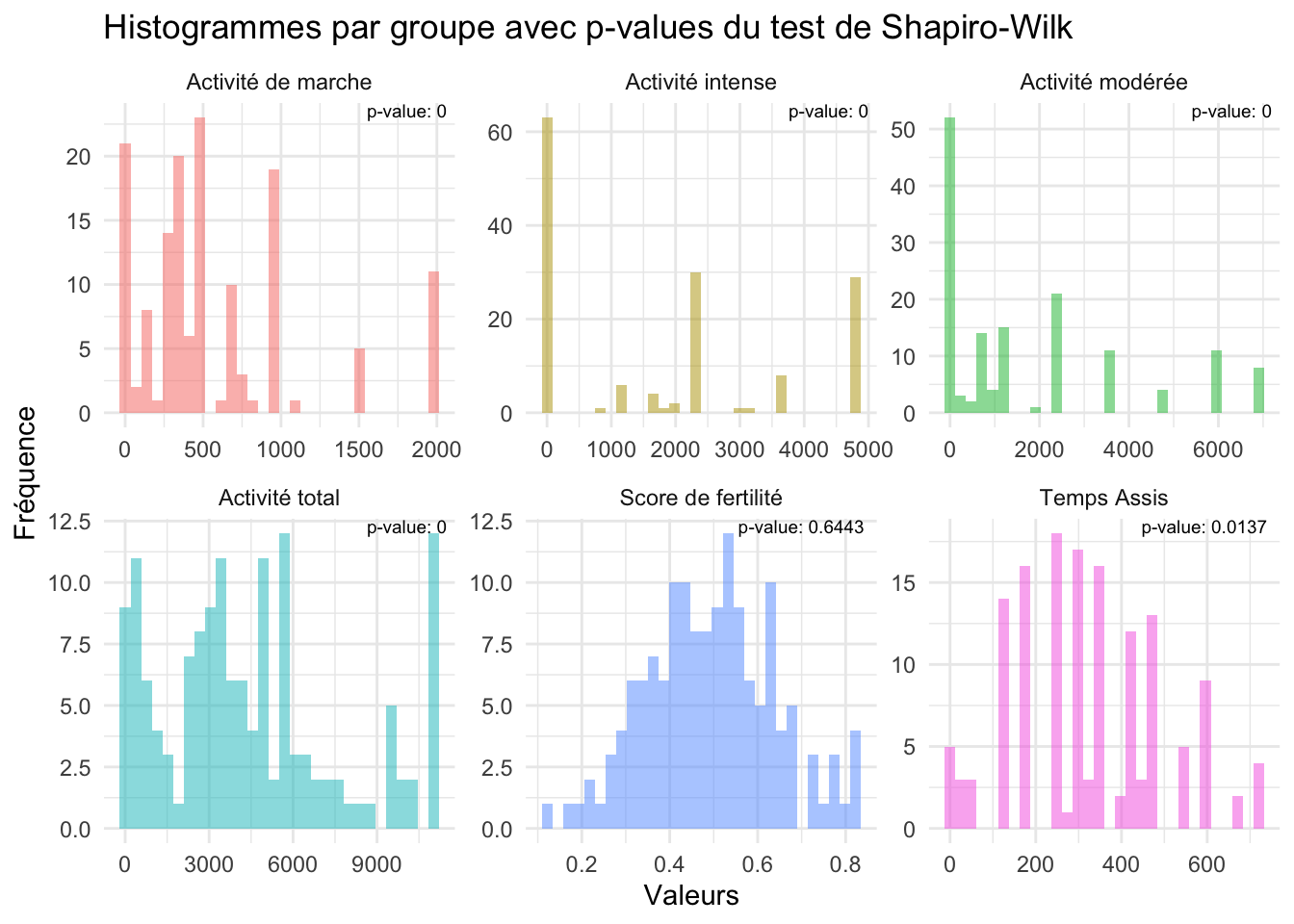
data_df <-data.frame(value =c(d1$Score.fertilité,d1$TempsAssis,d1$MarcheMET,d1$ModéréeMET,d1$IntensitéMET,d1$TotalMET),group =rep(c("Score de fertilité","Temps Assis","Activité de marche","Activité modérée","Activité intense","Activité total"),each =146))shapiro_results <- data_df %>%group_by(group) %>%summarise(shapiro_p =shapiro.test(value)$p.value)p <-ggplot(data_df, aes(x = value, fill = group)) +geom_histogram(bins =30, alpha =0.5) +labs(title ="Histogrammes par groupe avec p-values du test de Shapiro-Wilk", x ="Valeurs", y ="Fréquence") +facet_wrap(~ group, scales ="free") +theme_minimal() +theme(legend.position ="none") +geom_text(data = shapiro_results, aes(x =Inf, y =Inf, label =paste("p-value:", round(shapiro_p, 4))),hjust =1.1, vjust =1.1, size =2.5)
Seules la variables du score de fertilité présente une p-value supérier à 0,05 acceptant donc l’hypothèse H0 et la normalité de la distributions des valeurs du score de fertilité. Les p-values des autres variables étant trop inférieur.
4. Conclusion
L’analyse première de notre jeu de donnée montrent un total de 22 valeurs manquantes répartie dans les mesures du temps assis et de l’activité de marche. Le nouveau jeu de donnée (d1) créer tient compte de notre analyse et comporte les données de (d) avec l’imputation par les proches voisins et la winzorisation des données. L’observation de la normalité des distribution révèle une distribution normal significative pour le score de fertilité. Sans être significatif, le temps assis semblent suivre une tendance de normalité dans sa distribution.
Partie II : Analyse des données brutes
1. Comparaison des moyennes selon le status de fertilité
Hypothèse H0 : il n’y a pas de différence entre les moyennes des variables d’activité issus du groupe fertile et celle issus du groupe infertile
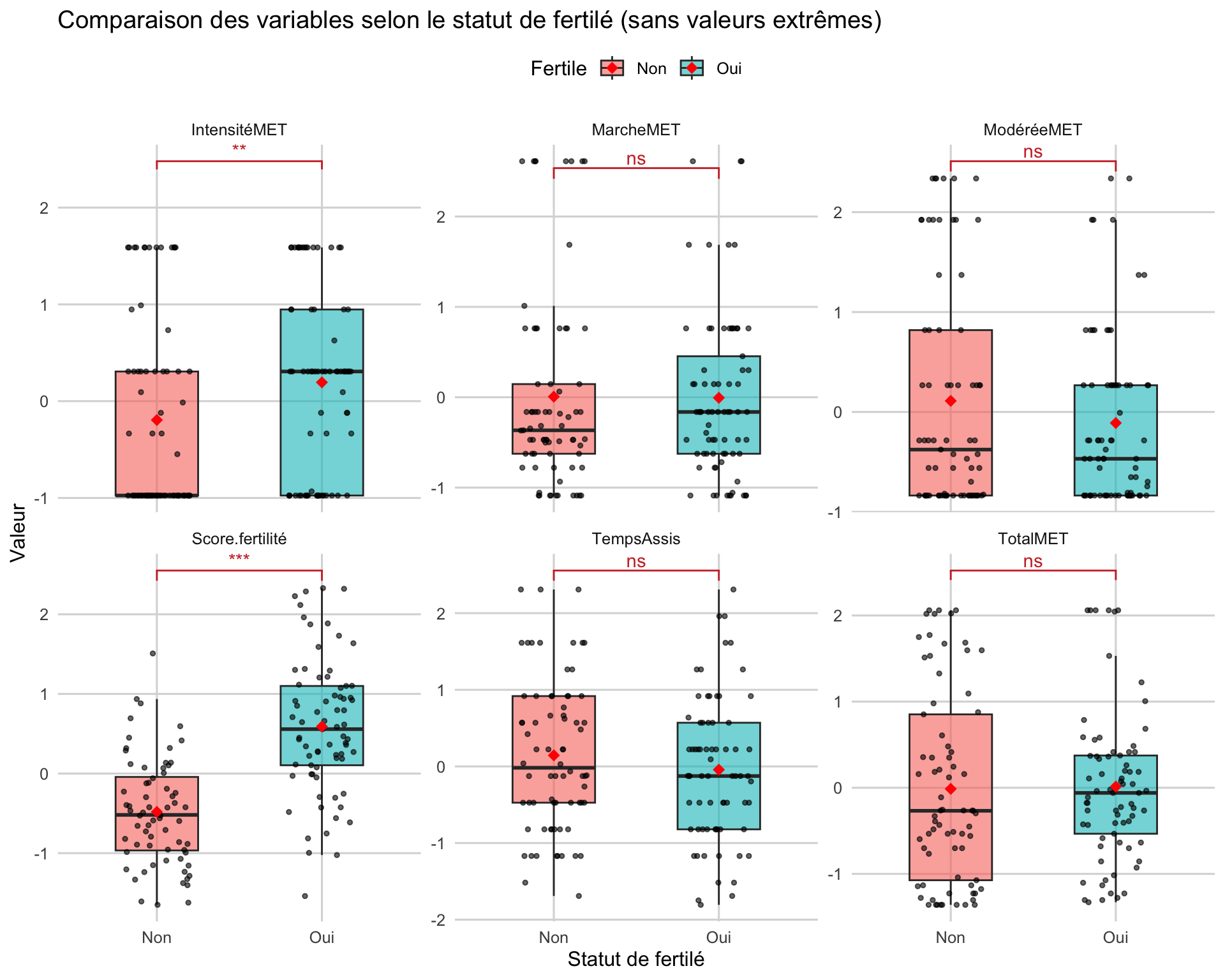
Ce qu’on observe ici c’est que seule 2 variables sont significativement différentes. Soit l’activité intense (p < 0,01) et le score de fertilité (p < 0,001). Les autres variables ne sont pas significativement différente.
2. Vérification d’un score représentant la fertilité
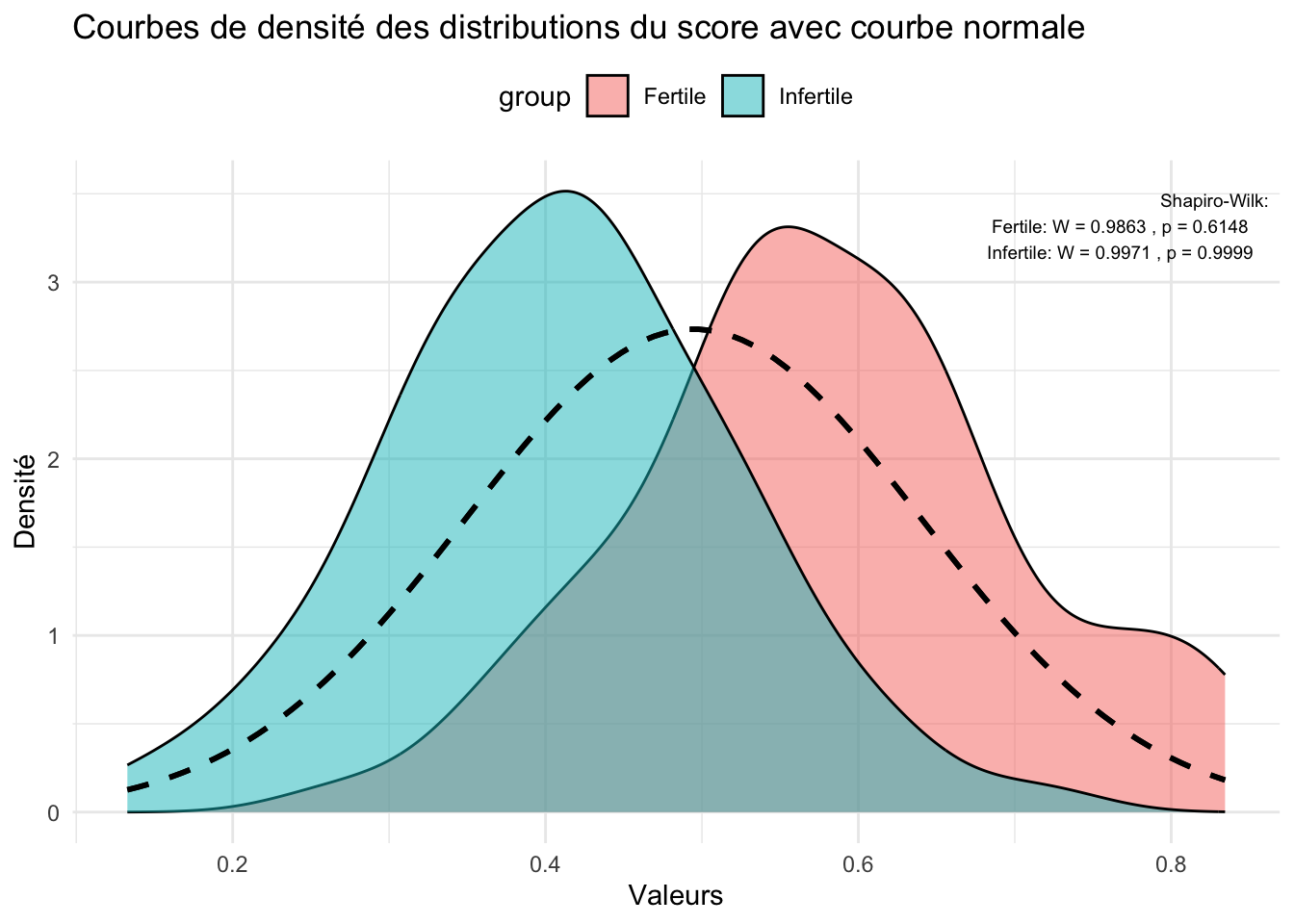
Hypothèse H0 : les distributions du score dans les groupes de fertilité suivent une loi normale
data <-data.frame(Fertile,Infertile)data_df2 <-data.frame(value =c(data$Fertile,data$Infertile),group =rep(c("Fertile","Infertile"),each =73))shapiro_Fertile <-shapiro.test(Fertile)shapiro_Infertile <-shapiro.test(Infertile)p2 <-ggplot(data_df2, aes(x = value, fill = group)) +geom_density(alpha =0.5) +stat_function(fun = dnorm, args =list(mean =mean(data_df2$value), sd =sd(data_df2$value)), color ="black", size =1, linetype ="dashed") +labs(title ="Courbes de densité des distributions du score avec courbe normale", x ="Valeurs", y ="Densité") +theme_minimal() +theme(legend.position ="top")
Warning: Using `size` aesthetic for lines was deprecated in ggplot2 3.4.0.
ℹ Please use `linewidth` instead.
p2 <- p2 +annotate("text", x =Inf, y =Inf, label =paste("Shapiro-Wilk:\nFertile: W =", round(shapiro_Fertile$statistic, 4), ", p =", round(shapiro_Fertile$p.value, 4), "\nInfertile: W =", round(shapiro_Infertile$statistic, 4), ", p =", round(shapiro_Infertile$p.value, 4)), hjust =1.1, vjust =1.5, size =2.5, color ="black", parse =FALSE)
On accepte bien l’hypothèse H0 qui montrent la normalité des distributions du score au sein du groupe fertile et infertile. On peut réaliser un test d’homogénéité de Student
Hypothèse H0 : il n’y a pas de différence significative entre les groupes fertiles et infertiles sur le score de fertilité
Voir le résultat
resultat_test
Welch Two Sample t-test
data: Fertile and Infertile
t = 8.8201, df = 142.35, p-value = 3.699e-15
alternative hypothesis: true difference in means is not equal to 0
95 percent confidence interval:
0.1336530 0.2108666
sample estimates:
mean of x mean of y
0.5807358 0.4084760
resultat_test
Welch Two Sample t-test
data: Fertile and Infertile
t = 8.8201, df = 142.35, p-value = 3.699e-15
alternative hypothesis: true difference in means is not equal to 0
95 percent confidence interval:
0.1336530 0.2108666
sample estimates:
mean of x mean of y
0.5807358 0.4084760
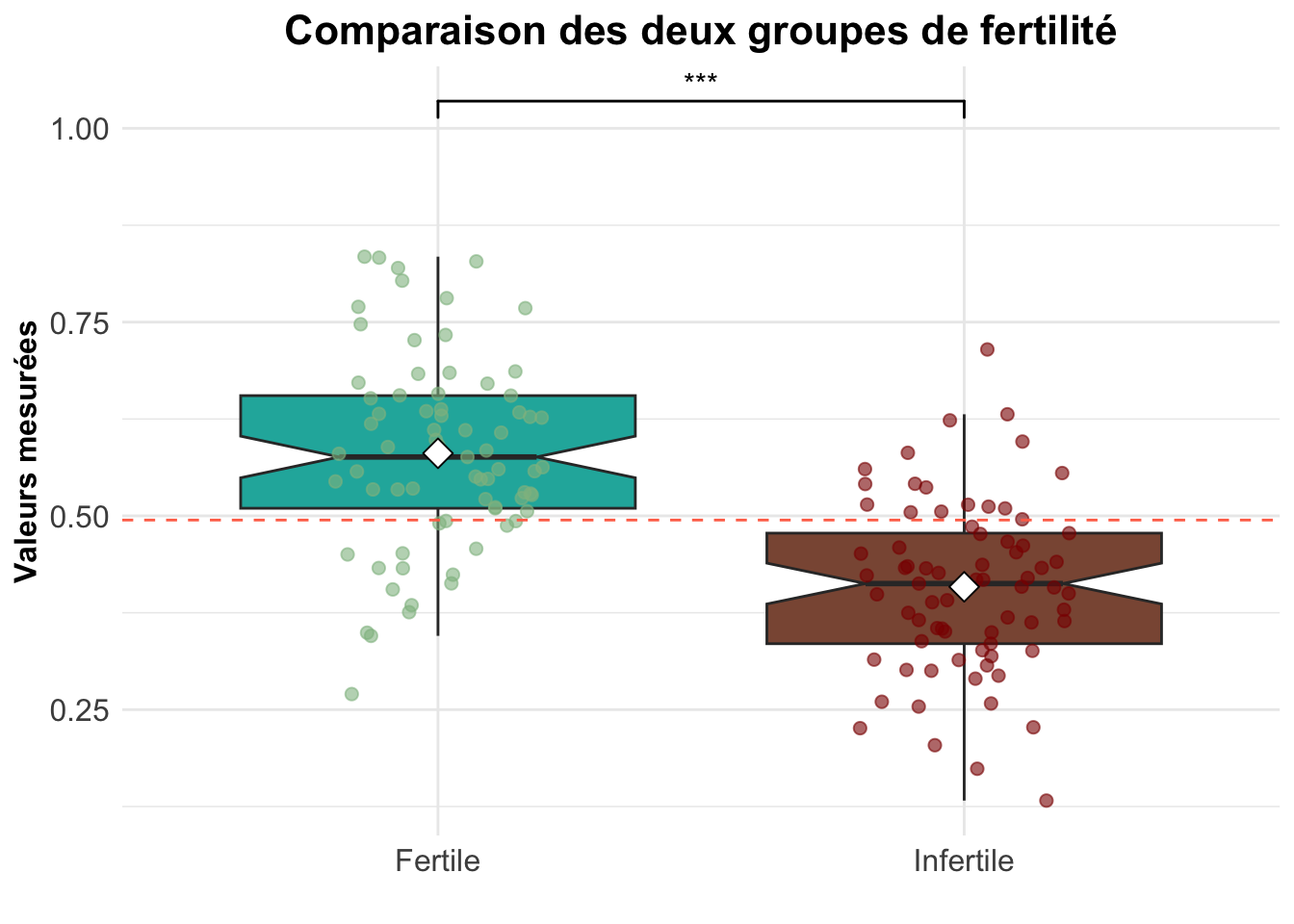
Avec un t = 8,82 on peut rejeté l’hypothèse nul avec un risque alpha de 0,001. Le score de fertilité est significativement différente entre le groupe fertile et infertile. De ce fait, un score élevé est associé à au groupe d’individus fertile et un score plus faible, au groupe d’infertile.
Le score de fertilité permet bien de distinguer de manière significatif une population fertile d’une population infertile.
3. Corrélation des variables
Voir le code
# Matrice de corrélation non paramétrique de Spearmancor_matrix <-cor(d1, use ="pairwise.complete.obs", method ="spearman")# p-valueget_pvalue <-function(x, y) { test <-cor.test(x, y, method ="spearman")return(test$p.value)}# Matrice de p-valuesp_matrix <-sapply(d1, function(x) sapply(d1, function(y) get_pvalue(x, y)))p_adjusted <-p.adjust(as.vector(p_matrix), method ="BH")cor_long <-as.data.frame(as.table(cor_matrix))p_long <-as.data.frame(as.table(p_matrix))colnames(cor_long) <-c("Var1", "Var2", "Correlation")colnames(p_long) <-c("Var1", "Var2", "P_value")# Ajouter les p-values corrigéesp_long$P_value_corrected <- p_adjustedp_long$Significance <-cut(p_long$P_value, breaks =c(-Inf, 0.001, 0.01, 0.05, Inf), labels =c("***", "**", "*", ""), right =TRUE)p_long$Significance <-as.character(p_long$Significance) # Convertir en caractère# Fusionner les matrices de corrélation et de p-valuescor_p_long <-merge(cor_long, p_long[, c("Var1", "Var2", "P_value_corrected")], by =c("Var1", "Var2"))# Fusionner avec les p-values d'originecor_p_long <-merge(cor_long, p_long, by =c("Var1", "Var2"))
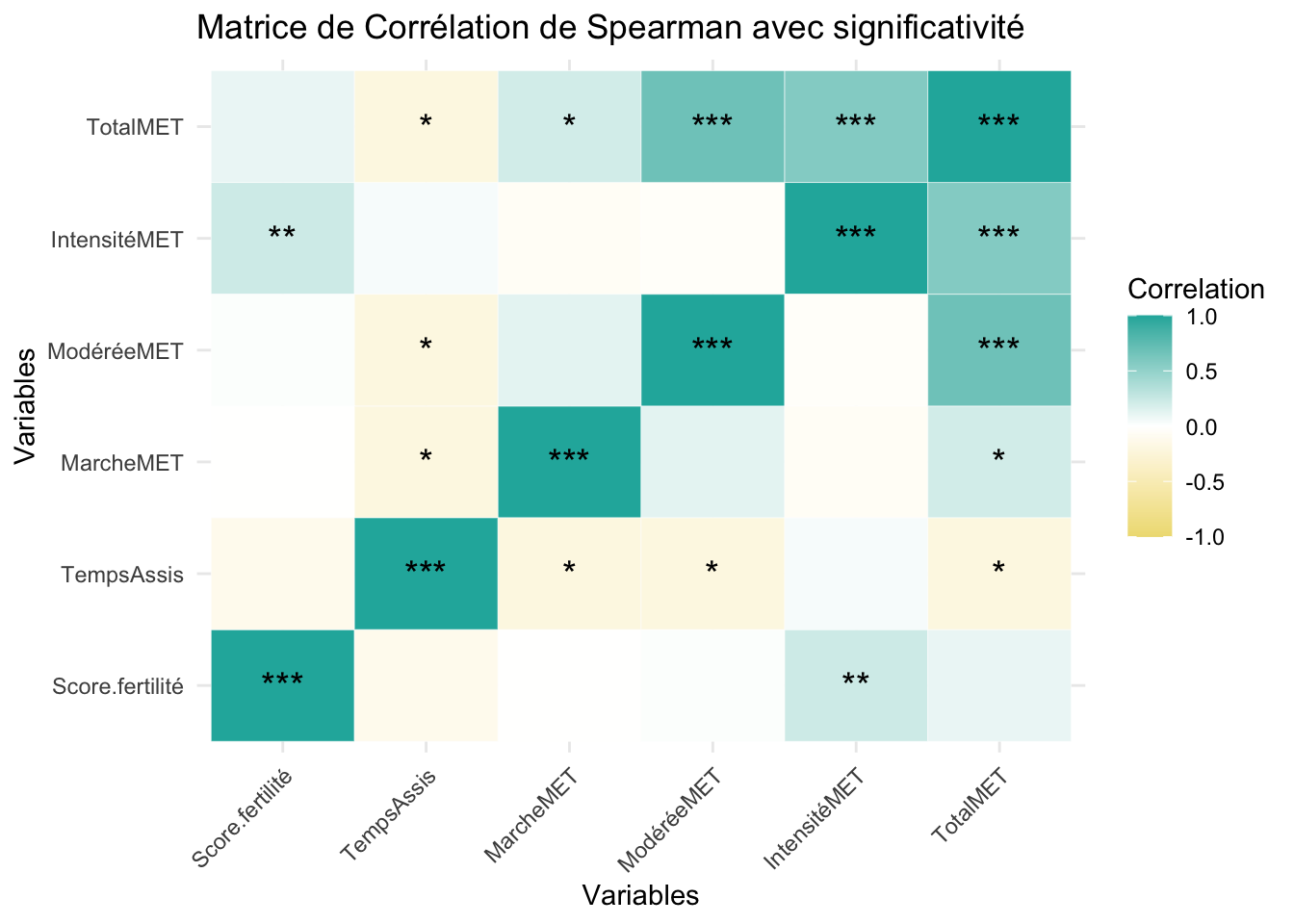
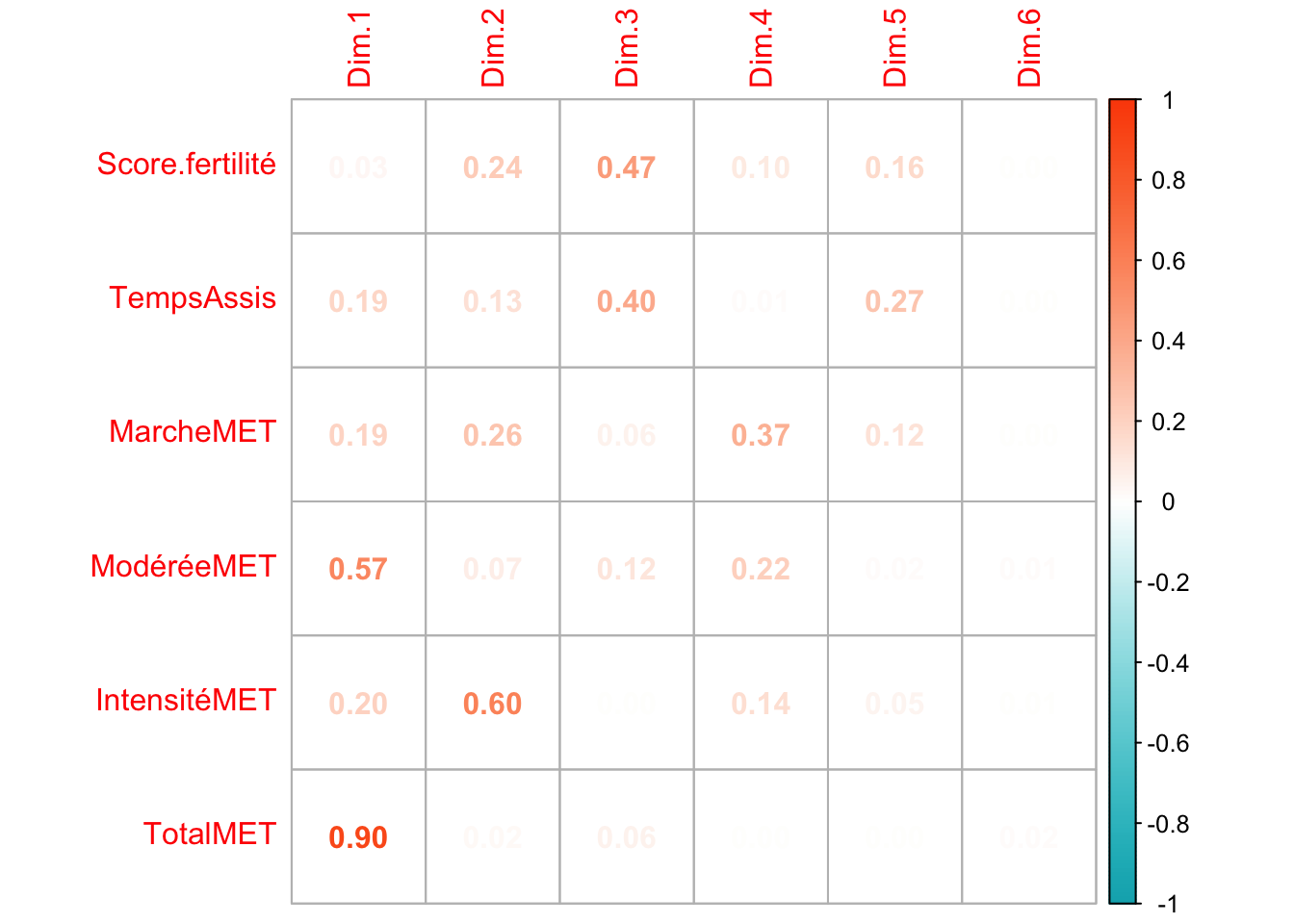
La corrélation des variables semble indiquer une cohérence nécessaire dans le cadre de mesures réalisées par autodéclaration. Le temps assis est significativement corrélé négativement aux variables d’activité physique, ce qui valide la cohérence de nos observations. Le temps d’activité total est, comme attendu, corrélé avec les autres sous-variables d’activité physique. Le score d’IA n’est, quant à lui, significativement corrélé qu’avec le score d’activité physique intense.
4. Régression linéaire sur le score de fertilité
Voir le code
# Restructurer les donnéesd1_melted <-melt(d1, id.vars ="Score.fertilité", variable.name ="Variable", value.name ="Valeur")# Fonction pour ajuster le modèle et récupérer les coefficients, p-values, et symboles de significativitéget_regression_info <-function(data) { model <-lm(Score.fertilité ~ Valeur, data = data) summary_model <-summary(model) coeff <- summary_model$coefficients[2, 1] p_value <- summary_model$coefficients[2, 4]# Déterminer le symbole de significativité significance_symbol <-ifelse(p_value <0.001, "***",ifelse(p_value <0.01, "**",ifelse(p_value <0.05, "*", "")))return(data.frame(Coeff = coeff, p_value = p_value, Significance = significance_symbol))}# Appliquer la fonction à chaque variableregression_results <- d1_melted %>%group_by(Variable) %>%do(get_regression_info(.)) %>%ungroup() # Dégrouper les résultats pour éviter des problèmes lors de l'affichage# Tracer les régressions avec coefficients et p-valuesp3 <-ggplot(d1_melted, aes(x = Valeur, y = Score.fertilité, color = Variable)) +geom_point() +# Ajoute les pointsgeom_smooth(method ="lm", se =FALSE) +# Ajoute les lignes de régressionlabs(title ="Régressions des variables sur le score de fertilité", x ="Valeur des Variables Explicatives", y ="Score de Fertilité") +theme_minimal()# Ajouter les coefficients et p-values sur le graphique avec symboles de significativité# Créer une position pour chaque textetext_positions <-data.frame(Variable = regression_results$Variable,x =max(d1_melted$Valeur, na.rm =TRUE) *0.85, # Position x fixey =seq(max(d1$Score.fertilité, na.rm =TRUE) *0.90, max(d1$Score.fertilité, na.rm =TRUE) *0.65, length.out =nrow(regression_results)) # Position y avec espacement)# Joindre les résultats de régression aux positionstext_data <-merge(regression_results, text_positions, by ="Variable")# Tracer le graphique avec les textes et les symbolesp3 <- p3 +geom_text(data = text_data, aes(x = x, y = y, label =sprintf("Coeff: %.2f\np-value: %.3f\n%s", Coeff, p_value, Significance)), hjust =1, vjust =1, # Ajustement de la positionsize =4, check_overlap =TRUE)# Convertir en graphique interactifinteractive_plot <-ggplotly(p3)
`geom_smooth()` using formula = 'y ~ x'
La régression linéaire montre qu’il existe une influence positive et significative de l’activité physique intense sur le score de fertilité. Même si la p-value reste discutable car supérieure à 0,05, le temps assis ne semble pas modifier le score de fertilité. La régression logistique binaire sur le facteur de fertilité n’a pas donné de résultats concluants.
Visualisation en 3 dimensions
Les variables d’activités physique intense (p-value < 0,05) et d’activité physique total (p-value 0,3) semblent être les varirables les plus impactant sur le score de fertilité
5. Conclusion
Dans l’observation brute, les données de l’activité physique intense et du score sont les seules variables dont la moyenne est significativement différente entre les individus du groupe fertile et ceux du groupe infertile. Le score de fertilité est significativement différent, ce qui indique qu’il peut représenter un potentiel lien entre le facteur binaire “fertile” et “infertile” et des variables continues impactant indirectement la fertilité, comme les variables d’activité physique présentées ici. La corrélation des variables s’est révélée cohérente. Le temps assis, représentant la sédentarité, est significativement corrélé négativement avec les variables d’activité physique. Le temps d’activité physique intense semble être lié à une probabilité de fertilité plus élevée ; cette augmentation des chances pourrait résulter d’une amélioration du score et constituerait une variable parmi des centaines d’autres susceptibles d’influencer potentiellement la fertilité.
Partie III : Réalisation de l’Analyse factorielle
Cette étape va se consacrer à la projection et à la compression des données par ACP pour n’en garder que celles qui portent suffisament d’informations pour expliquer au mieux notre problématique. La normalisation des données est automatiquement réalisées par la fonction PCA de FactoMineR.
On utilise le test de KMO pour vérifier la fiabilité de nos interprétations. Les résultats sont regroupés dans le tableau suivant :
Variable
Test de KMO
Score de fertilité
0,51
Temps Assis
0,63
Marche
0,18
Activité modérée
0,24
Activité intense
0,16
Activité total
0,32
Le score de KMO se montrent particulièrement restreignant concernant l’utilisation de nos variables dans une analyse PCA. Les résultats ne représenteront pas avec certitude la réalité de ce que peut apporter nos variables sur la fertilité. Cependant, la p-value du test de Bartlett de 1,95e-76 contredit le score de KMO.
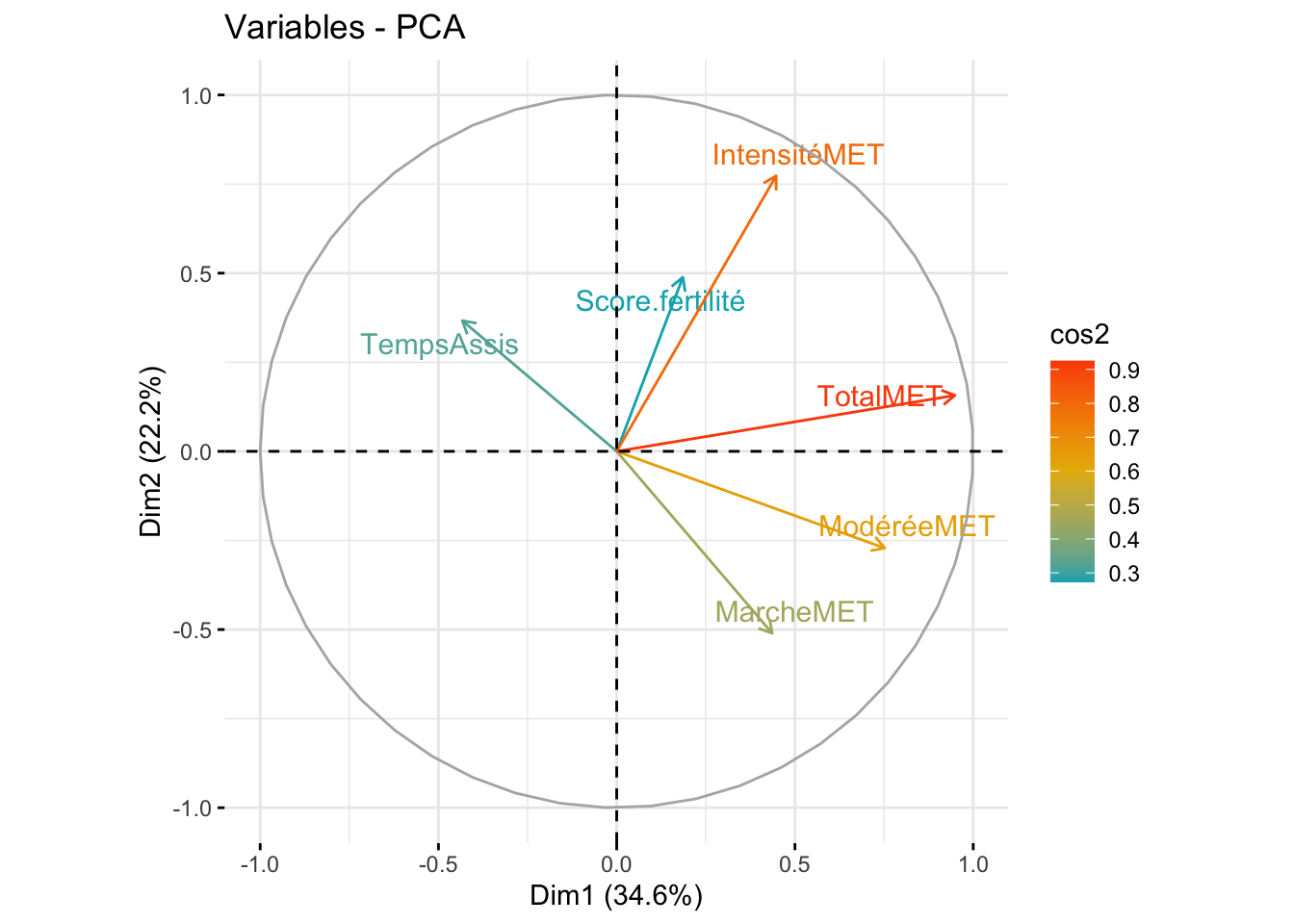
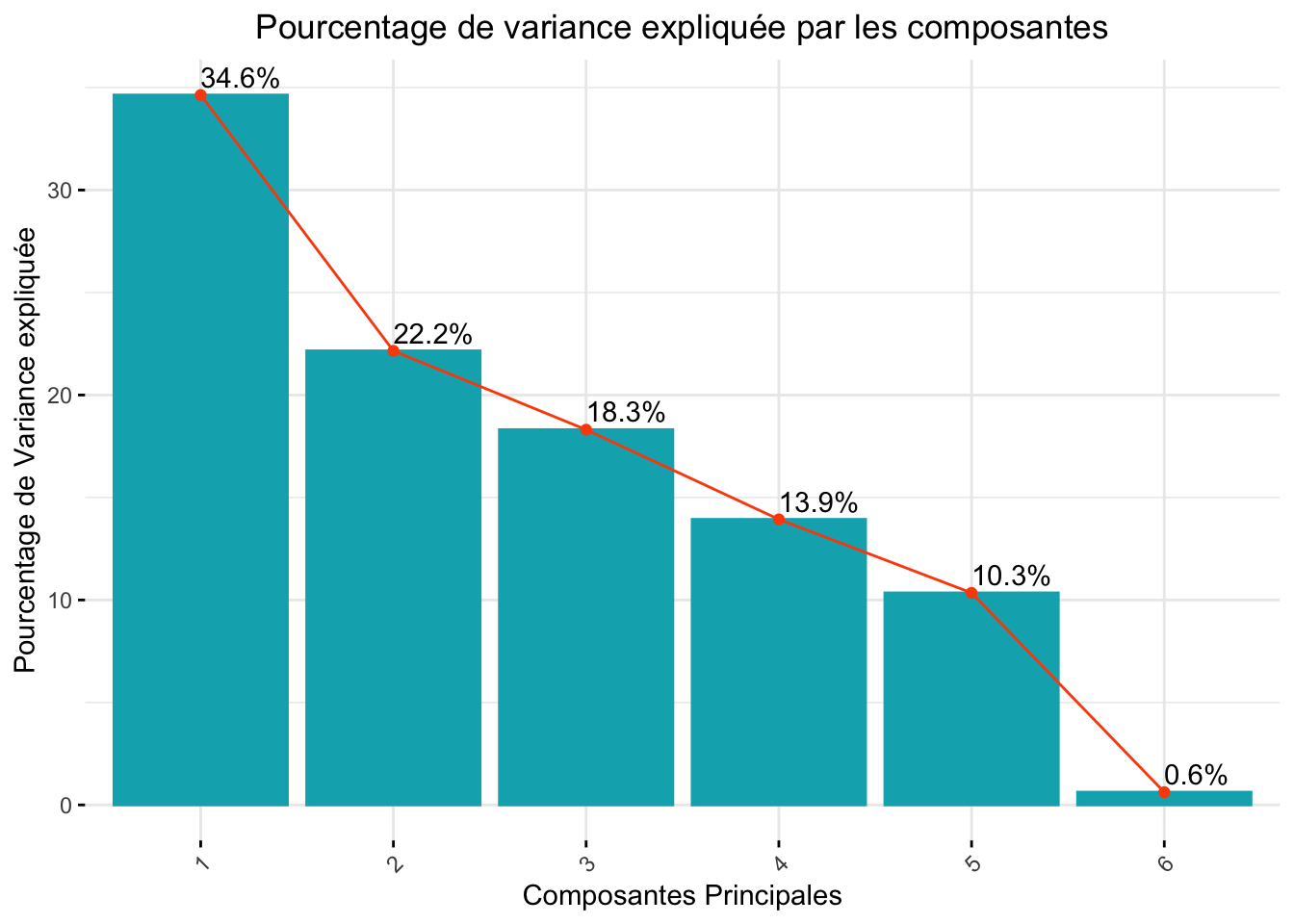
Dans une première analyse, l’axe 1 semble représenter plus d’un tiers de nos observations. Les valeurs liées à l’activité semblent bien être prises en compte, contrairement au score d’IA qui semble avoir un poids plus faible dans notre représentation. La représentation individuelle est globalement homogène.
Visualisation de la distribution de l’inertie des axes
res <-get_pca_var(res.pca)
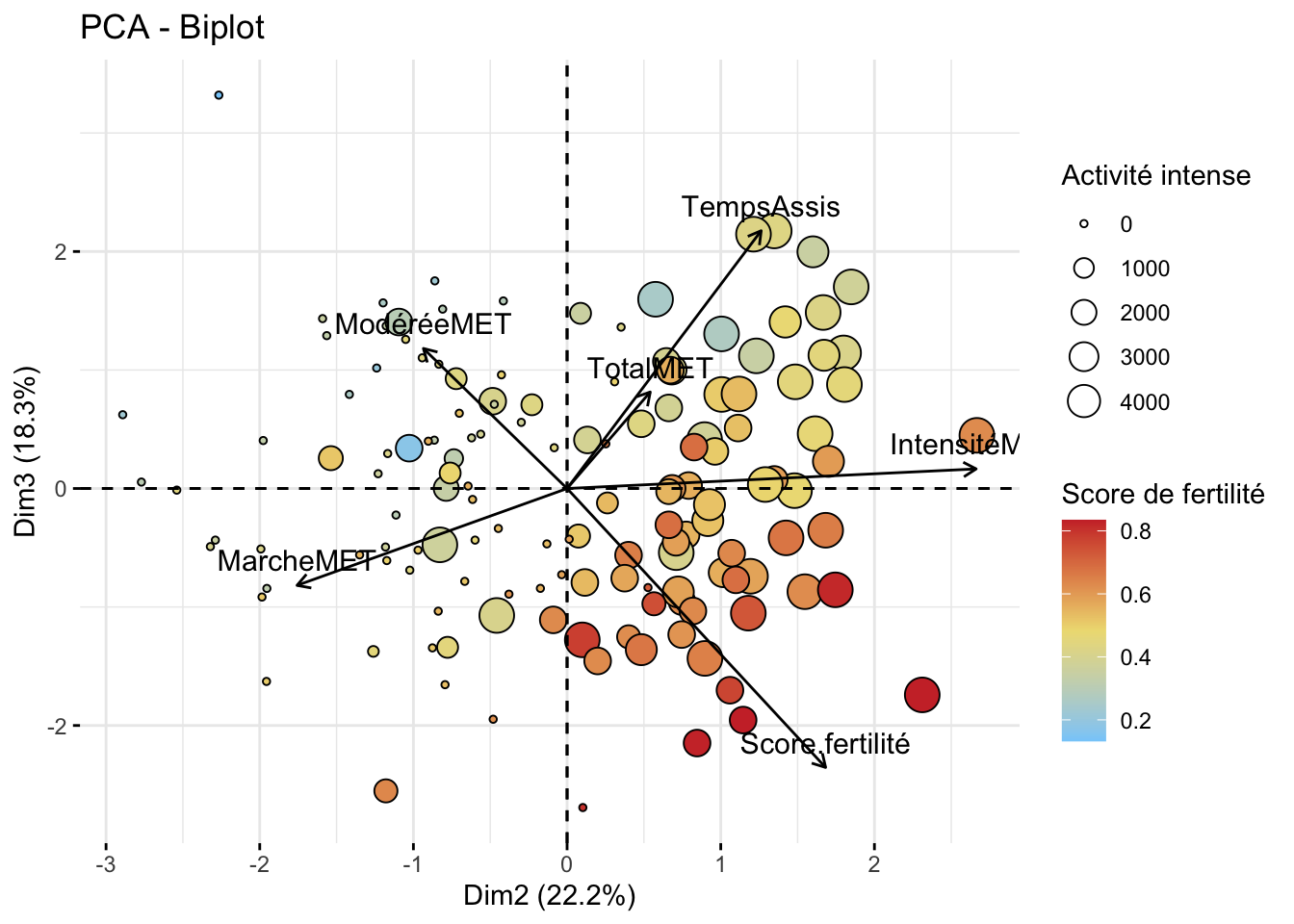
Les deux premiers axes de l’analyse expriment plus de la moitié de l’inertie totale du jeu de données. Le premier plan représente convenablement la variabilité contenue dans une grande partie du jeu de données actif. Au sein de la première dimension, c’est l’activité totale qui est la variable la plus représentée. De manière générale, ce sont les valeurs liées à l’activité physique qui participent le plus à la première dimension. Le score de fertilité intervient principalement dans la troisième dimension avec le temps assis, mais avec une très faible prise en compte des valeurs d’activités physiques. Cependant, il peut être intéressant d’observer cette dimension avec la première.
Analyse de la répartition des variables
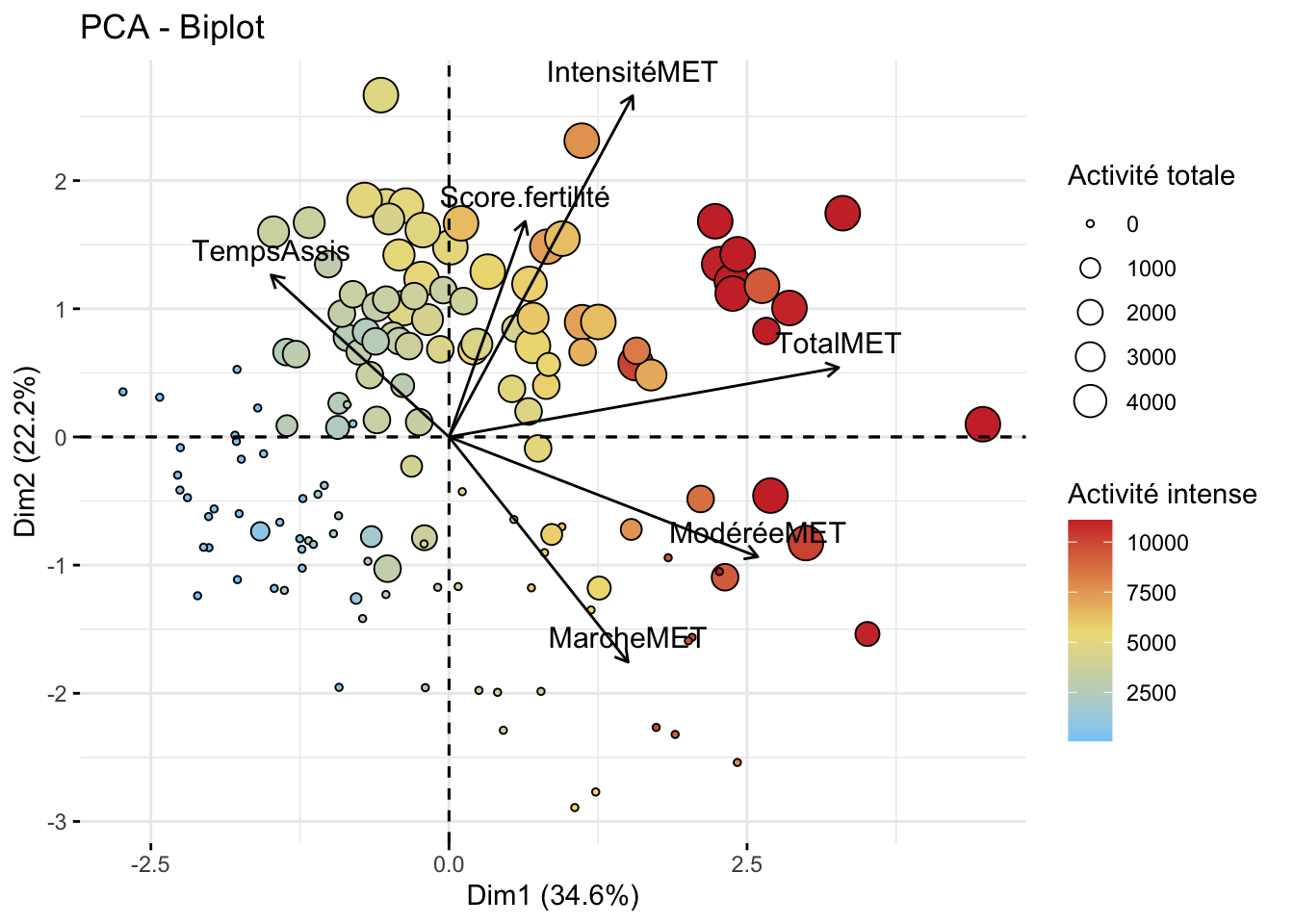
Dans une première analyse, on s’intéresse aux dimensions 1 et 2, qui semblent bien caractériser les individus ayant une forte activité physique et donc un profil sportif élevé. Les individus sont regroupés dans les parties supérieures, notamment dans le quadrant supérieur droit. Il est nécessaire de visualiser l’axe de la dimension 3 pour mettre en évidence le score. En le positionnant avec la dimension 2 (pour représenter l’activité physique intense), on observe un regroupement intéressant entre les individus ayant une activité physique intense et un bon score d’IA. Il est également pertinent d’observer les axes 1 et 3 pour positionner les profils sportifs (voir l’analyse PCA interactive).
Visualisation interractif de la PCA
Si le bouton ne marche pas, utiliser le lien externe : Visualisation PCA
Résultat de la PCA sur la fertilité
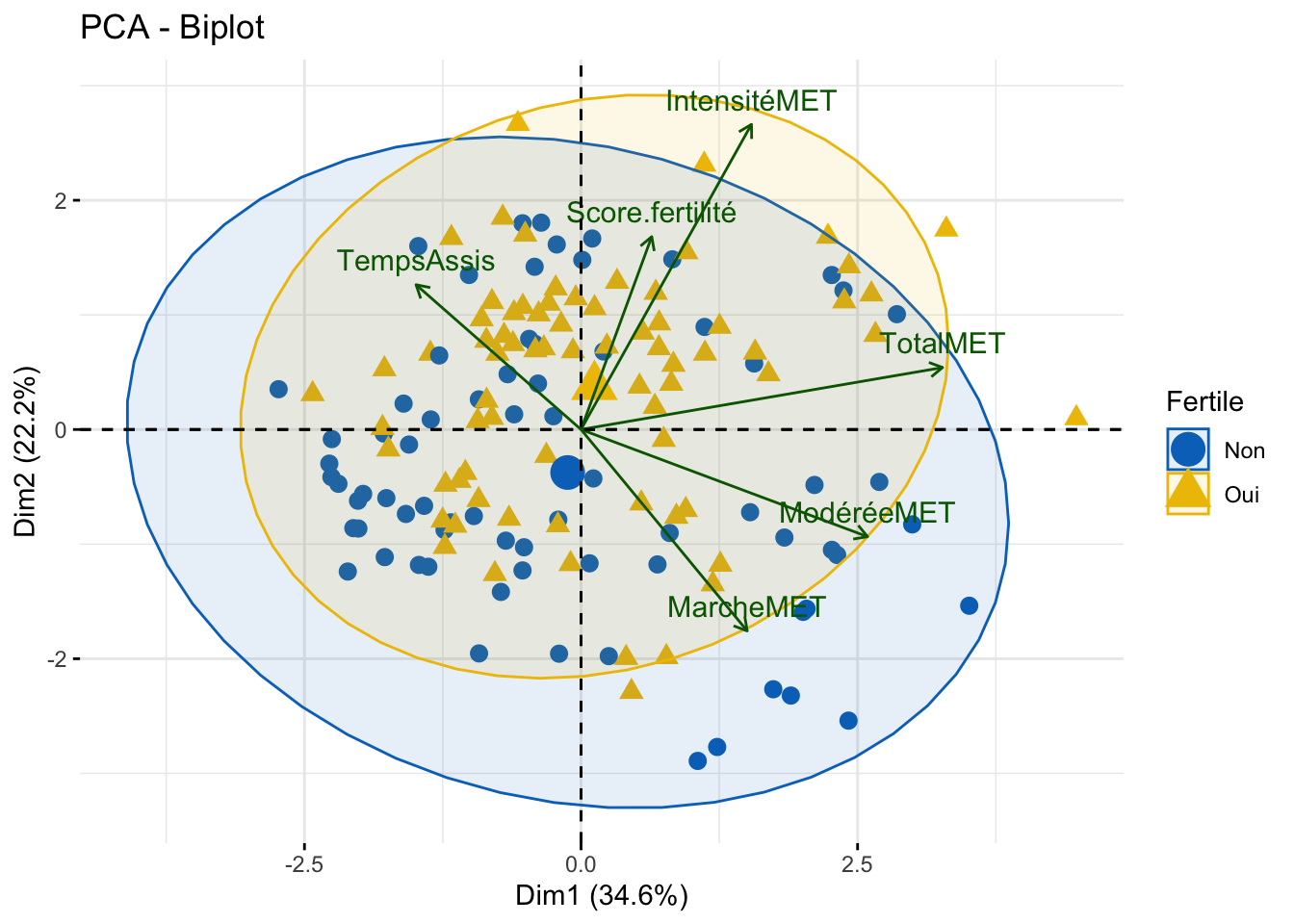
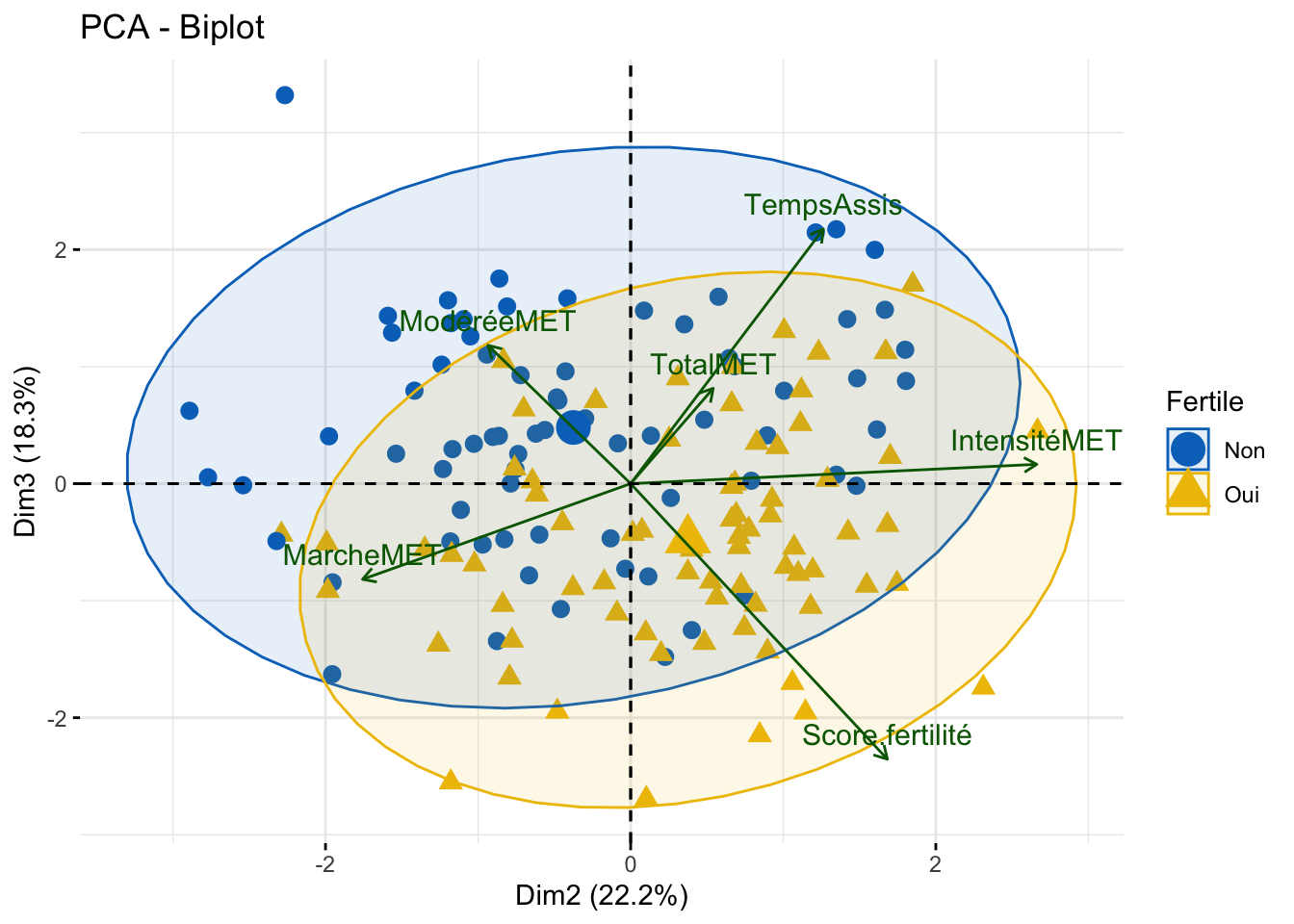
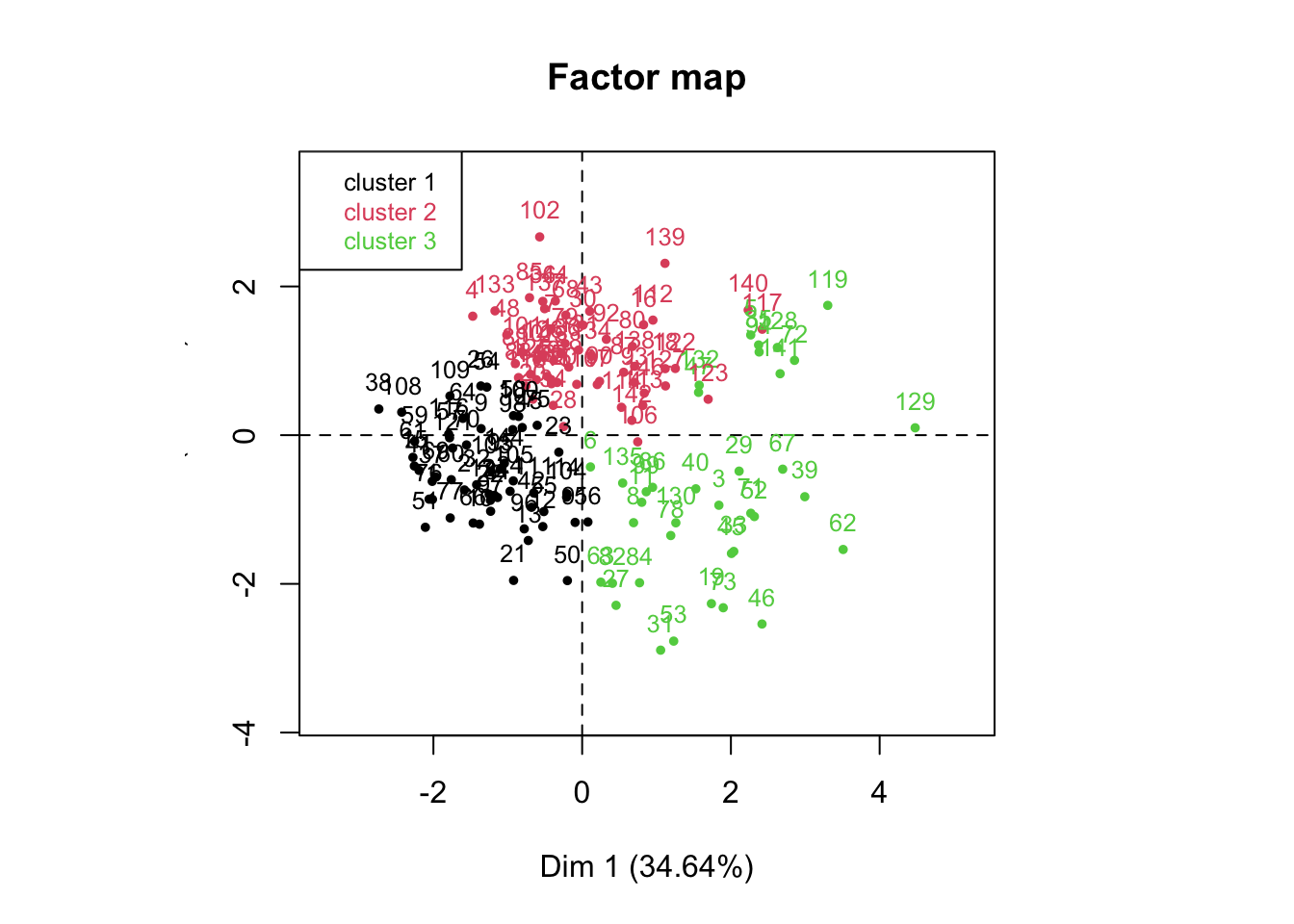
Pour terminer l’observation de la PCA, on regarde la répartition de la fertilité. Même en visant l’axe de dimension 3 qui est censé représenté le score, on s’apercoit que la PCA à dû mal à classer les groupes.
On remarque que les 2 groupes de fertilité sont bien séparés. Cependant, à l’intérieur de chaque groupe, se trouve une répartition homogène des variables.
Validation croisée du modèle
Voir le code
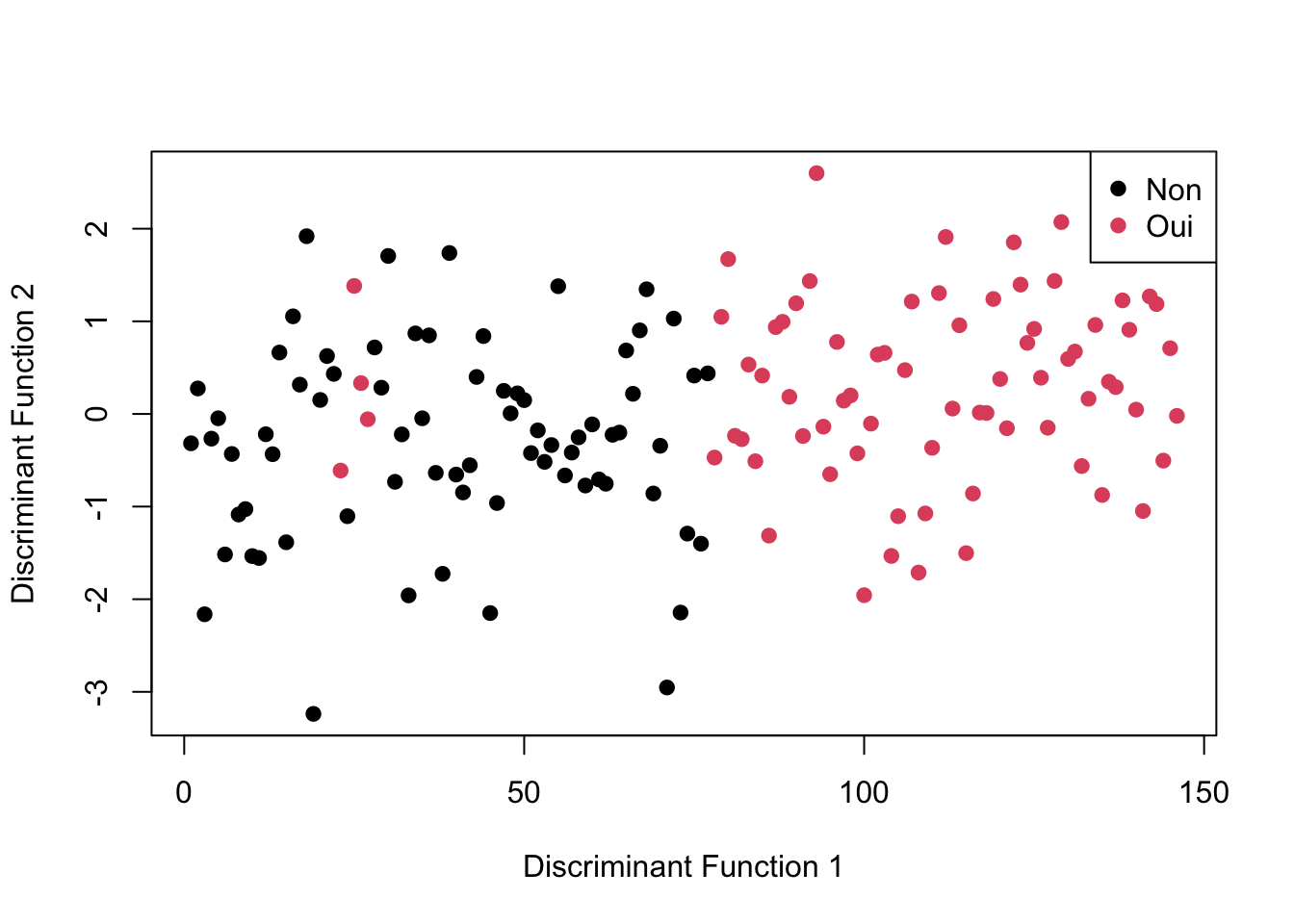
# Définir le nombre de foldsk <-10# Définir la méthode de validation croiséecontrol <-trainControl(method ="cv", number = k)# Ajuster le modèle LDA avec validation croiséelda_model <-train(Fertile ~ TempsAssis + MarcheMET + ModéréeMET + IntensitéMET + TotalMET, data = d9, method ="lda", trControl = control)
Bien que l’observation du graphique de l’analyse discriminante linéaire montre une bonne répartition des groupes sur la fertilité, la validation croisée (avec k=10) indique une précision de 0,59, ce qui ne permet pas de conclure à une bonne répartition des variables dans nos modèles de regroupement. De plus, le score de Kappa de Cohen est très faible (0,163), à peine supérieur à celui du hasard.
3. Amélioration par bootstrap
Normalité des distribution
Voir le code
d13=d1[,c(2,3,4,5,6)]bootstrap_mean <-function(data, column_name, B =1000) { n <-nrow(data) means <-numeric(B)for (i in1:B) { sample_indices <-sample(1:n, size = n, replace =TRUE) means[i] <-mean(data[[column_name]][sample_indices]) }return(means)}B <-1000bootstrap_results <-list()for (var innames(d13)) { bootstrap_results[[var]] <-bootstrap_mean(d13, var, B)}ci_results <-list()for (var innames(d1)) { ci_lower <-quantile(bootstrap_results[[var]], 0.025) ci_upper <-quantile(bootstrap_results[[var]], 0.975) ci_results[[var]] <-c(lower = ci_lower, upper = ci_upper)}real_means <-sapply(d13, mean)shapiro_results <-sapply(bootstrap_results, function(x) shapiro.test(x)$p.value)shapiro_df <-data.frame(Variable =names(shapiro_results), p_value = shapiro_results)
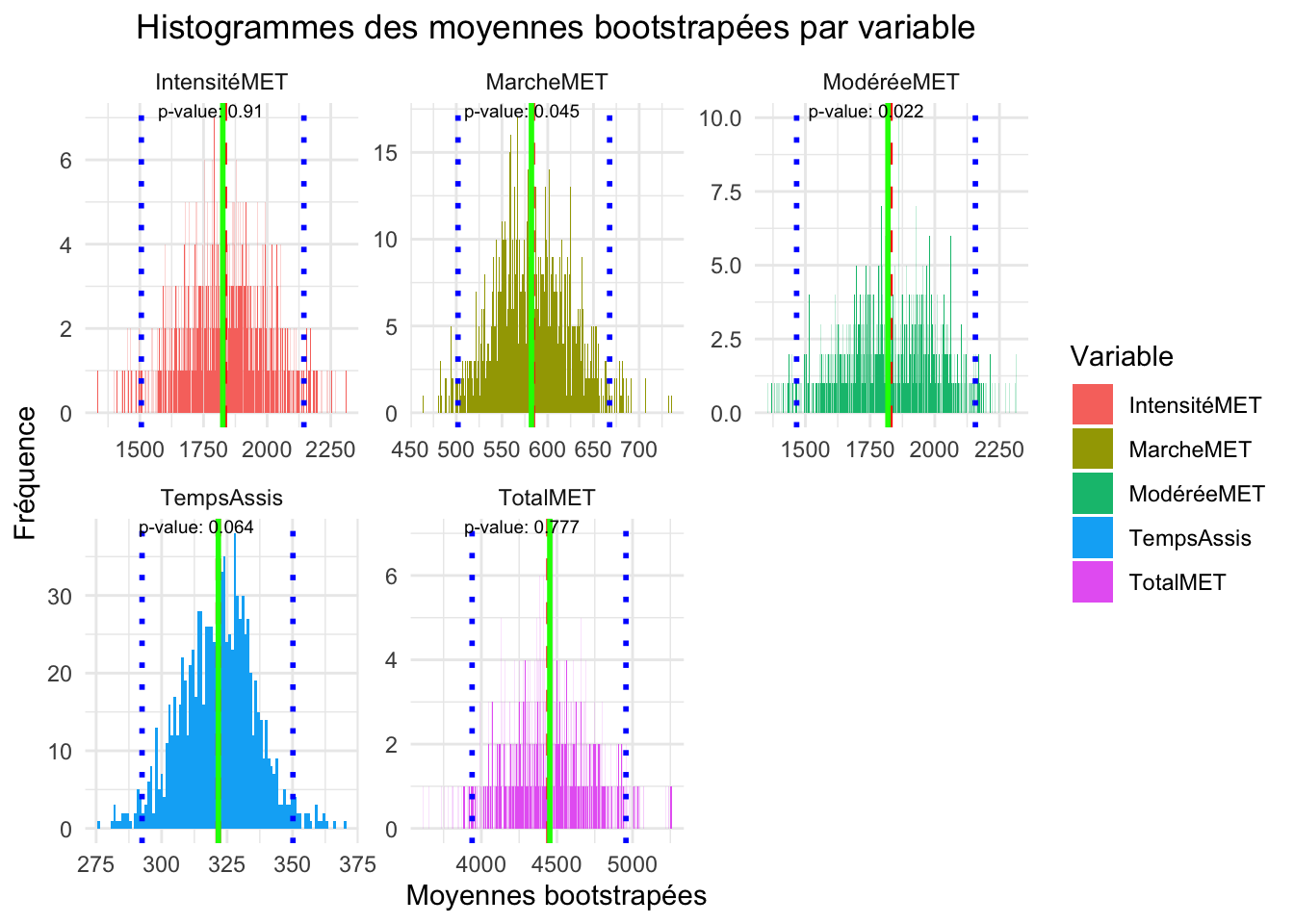
Pour rappel, l’axe des abscisses représente les valeurs des moyennes bootstrapées. Les intervalles (bins) regroupent un nombre nn de valeurs. L’axe des ordonnées montre le nombre de fois que les valeurs de la variable tombent dans les bins (on parle de densité de valeurs). La symétrie indique la normalité des distributions, avec des p-values confirmant le test de Shapiro. Les moyennes représentent généralement une tendance (fréquence élevée). L’équivalence entre la moyenne bootstrapée et la moyenne réelle montre une bonne représentation de la population.
Un test de Student n’a pas montré de différence significative dans les variables, à l’exception de l’activité physique intense et du score de fertilité, dont la significativité des différences a déjà été démontrée dans les données réelles.
Régression linéaire et logistique
Régression logistique
Voir le code
d15=d1d15 <-cbind(d15,APH$Fertile)colnames(d15)[ncol(d15)] <-"Fertile"# Fonction de bootstrapbootstrap_lm <-function(data, indices) { d15 <- data[indices, ] model <-glm(Fertile ~IntensitéMET + ModéréeMET + MarcheMET + TempsAssis + Score.fertilité + TotalMET, data = d15,family = binomial)return(coef(model))}library(boot)# Application du bootstrap avec 1000 répétitionsbootstrap_results <-boot(data = d15, statistic = bootstrap_lm, R =1000)# Extraire les coefficients pour chaque échantillon bootstrapintercepts <- bootstrap_results$t[, 1]coefficients_x1 <- bootstrap_results$t[, 2] coefficients_x2 <- bootstrap_results$t[, 3] coefficients_x3 <- bootstrap_results$t[, 4] coefficients_x4 <- bootstrap_results$t[, 5]coefficients_x5 <- bootstrap_results$t[, 6]coefficients_x6 <- bootstrap_results$t[, 7] coefficients_long <-data.frame(Coefficient =c(rep("Intercept", length(intercepts)), rep("IntensitéMET", length(coefficients_x1)), rep("ModéréeMET", length(coefficients_x2)), rep("MarcheMET", length(coefficients_x3)), rep("TempsAssis", length(coefficients_x4)),rep("Score.fertilité",length(coefficients_x5)),rep("TotalMET",length(coefficients_x6))),Value =c(intercepts, coefficients_x1, coefficients_x2, coefficients_x3, coefficients_x4,coefficients_x5,coefficients_x6))# Calculer la moyenne +SD pour chaque coefficientmean_values <-aggregate(Value ~ Coefficient, data = coefficients_long, FUN = mean)sd_values <-aggregate(Value ~ Coefficient, data = coefficients_long, FUN = sd)# Calculer les p-valuesB <-1000p_values <-sapply(1:nrow(mean_values), function(i) {# t-statistic t_stat <- mean_values$Value[i] / (sd_values$Value[i] /sqrt(B)) # Diviser par sqrt(B)# Degrés de liberté pour bootstrap (B - 1) df <- B -1# p-value bilatérale2* (1-pt(abs(t_stat), df = df)) # Utiliser df ajusté})# Ajouter les p-values aux moyennes dans une nouvelle data frameresults_df <-data.frame(Coefficient = mean_values$Coefficient,Mean = mean_values$Value,p_value = p_values)results_df$Odds_Ratio <-exp(results_df$Mean)
Résultats des Coefficients de Régression linéaire
Coefficient
Mean
p_value
Odds_Ratio
IntensitéMET
0.0004909
0
1.000491e+00
Intercept
-6.1762140
0
2.078300e-03
MarcheMET
0.0005912
0
1.000591e+00
ModéréeMET
0.0001919
0
1.000192e+00
Score.fertilité
13.1899123
0
5.349413e+05
TempsAssis
-0.0015514
0
9.984498e-01
TotalMET
-0.0003173
0
9.996827e-01
Régression linéaire
Voir le code
# Fonction de bootstrapbootstrap_lm2 <-function(data, indices) { d9 <- data[indices, ] model2 <-lm(Score.fertilité ~IntensitéMET + ModéréeMET + MarcheMET + TempsAssis + TotalMET, data = d9)return(coef(model2))}# Application du bootstrap avec 1000 répétitionsbootstrap_results2 <-boot(data = d9, statistic = bootstrap_lm2, R =1000)# Extraire les coefficients pour chaque échantillon bootstrapintercepts2 <- bootstrap_results2$t[, 1]coefficients_x11 <- bootstrap_results2$t[, 2] coefficients_x22 <- bootstrap_results2$t[, 3] coefficients_x33 <- bootstrap_results2$t[, 4] coefficients_x44 <- bootstrap_results2$t[, 5]coefficients_x55 <- bootstrap_results2$t[, 6]coefficients_long2 <-data.frame(Coefficient =c(rep("Intercept", length(intercepts2)), rep("IntensitéMET", length(coefficients_x11)), rep("ModéréeMET", length(coefficients_x22)), rep("MarcheMET", length(coefficients_x33)), rep("TempsAssis", length(coefficients_x44)),rep("TotalMET",length(coefficients_x55))),Value =c(intercepts2, coefficients_x11, coefficients_x22, coefficients_x33, coefficients_x44,coefficients_x55))# Calculer la moyenne +SD pour chaque coefficientmean_values2 <-aggregate(Value ~ Coefficient, data = coefficients_long2, FUN = mean)sd_values2 <-aggregate(Value ~ Coefficient, data = coefficients_long2, FUN = sd)# Calculer les p-valuesB <-1000p_values2 <-sapply(1:nrow(mean_values2), function(i) {# t-statistic t_stat2 <- mean_values2$Value[i] / (sd_values2$Value[i] /sqrt(B)) # Diviser par sqrt(B)# Degrés de liberté pour bootstrap (B - 1) df2 <- B -1# p-value bilatérale2* (1-pt(abs(t_stat2), df = df2)) # Utiliser df ajusté})# Ajouter les p-values aux moyennes dans une nouvelle data frameresults_df2 <-data.frame(Coefficient = mean_values2$Coefficient,Mean = mean_values2$Value,p_value = p_values2)results_df2$Odds_Ratio <-exp(results_df2$Mean)
Résultats des Coefficients de Régression logistique
Coefficient
Mean
p_value
Odds_Ratio
IntensitéMET
0.0000289
0
1.0000289
Intercept
0.5406642
0
1.7171469
MarcheMET
-0.0000116
0
0.9999884
ModéréeMET
0.0000090
0
1.0000090
TempsAssis
-0.0001780
0
0.9998220
TotalMET
-0.0000113
0
0.9999887
4. Conclusion
Avec un score KMO moyen de 0.34, les variables sont difficilement interprétable dans le cadre d’une ACP, par conséquent les résultats, aussi interprétable qu’ils soient ne permettront de conclure efficacement sur la situation. La distribution des axes est assez hétérogène même si les deux premiers axes représentent plus de la moitiers des différences entre les individus. Sur la premières dimension, les individus à forte activités semblent se rassemblé à droite de la représentation graphique, là ou sur l’axe 2, la répartition semblent plus homogène. Le score de fertilité quant a lui est bien représenté à droite de la 3ème dimension mais il est à noté que les individus à forte activité physique semblent rejoindre le groupement des individus au score plus intense ce qui laisse suggérer une confirmation dans la corrélation des deux variables observé lors de matrice de corrélation. La projection de la fertilité sur la PCA est très hétérogène. Les régression obtenue suite à l’analyse en bootstrap, offrent des p-value largement interprétable mais la fiabilité de ces interprétation est remis en cause par une incohérence issus de la variable d’activité totale. En se retrouvent d’une influence négative sur la fertilité alors qu’elle est issus des activités physique modéré et intense qui ressortent positif pour cette même fertilité. La même observation est obtenu pour la régression linéaire.
Partie IV : Classification des données
Faisabilité de l’analyse de clustering
On vérifie la faisabilité de l’analyse en clustering en calculant la statistique de Hopkings.
Si l’indice de Hopkins est proche de 1, ça indique une tendance au regroupement et donc une argument possitifs à une analyse en cluster. Ici un score supérieur à 0,8 introduit bien une tendance au regroupement.
1. Détermination du nombre optimal de cluster
L’utilisation optimal de FactoMineR obligent à utiliser la partition ayant la plus grande perte relative d’inertie. On peut calculer cette indicateur via best.cutree. L’extension JLutils en propose une, la fonction regarde quelle serait la meilleure partition entre 3 et 20 classes
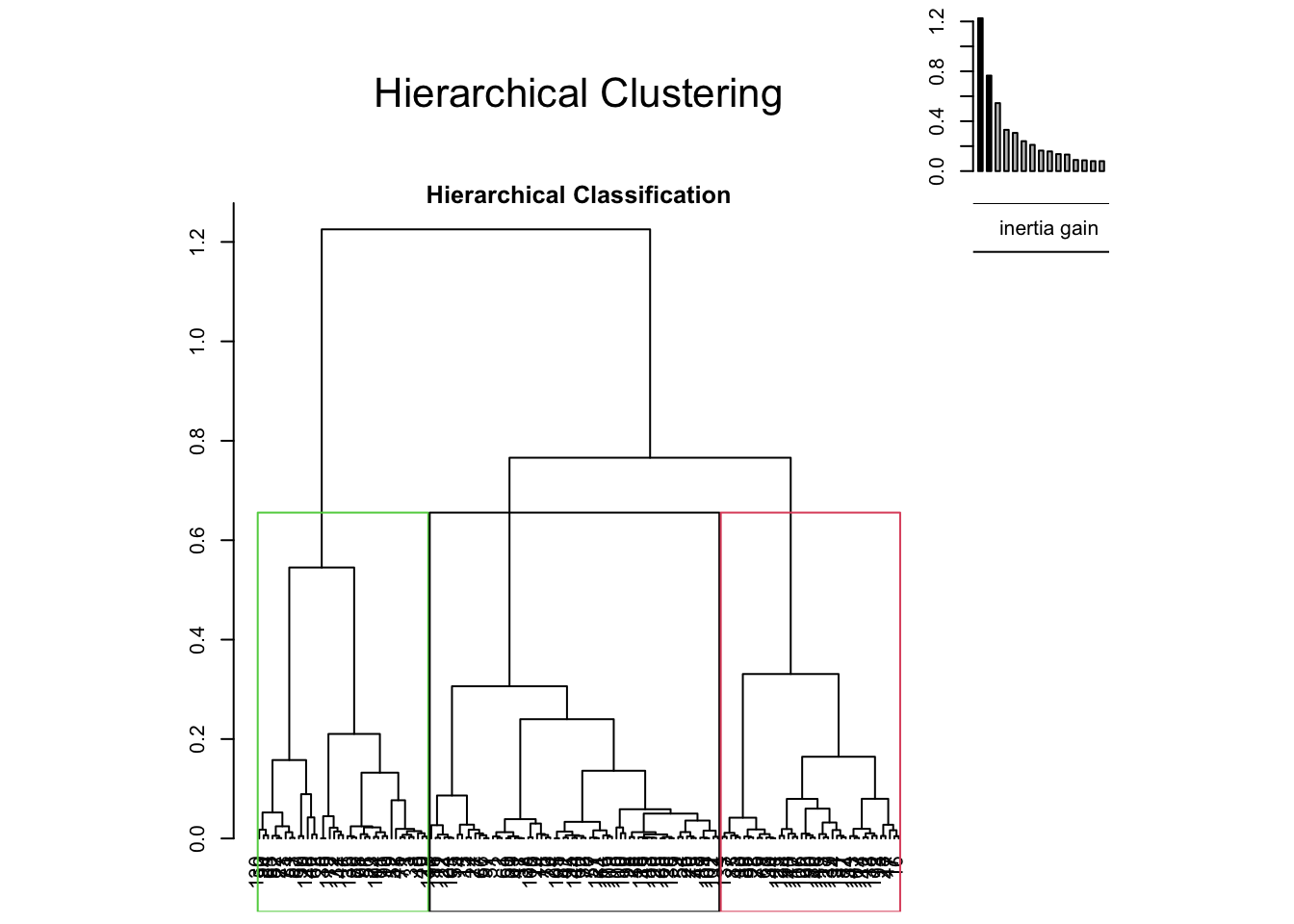
hc <-hclust(dist(d1), method="average")src<-source(url("https://raw.githubusercontent.com/larmarange/JLutils/master/R/clustering.R"))best<-best.cutree(hc)best
[1] 3
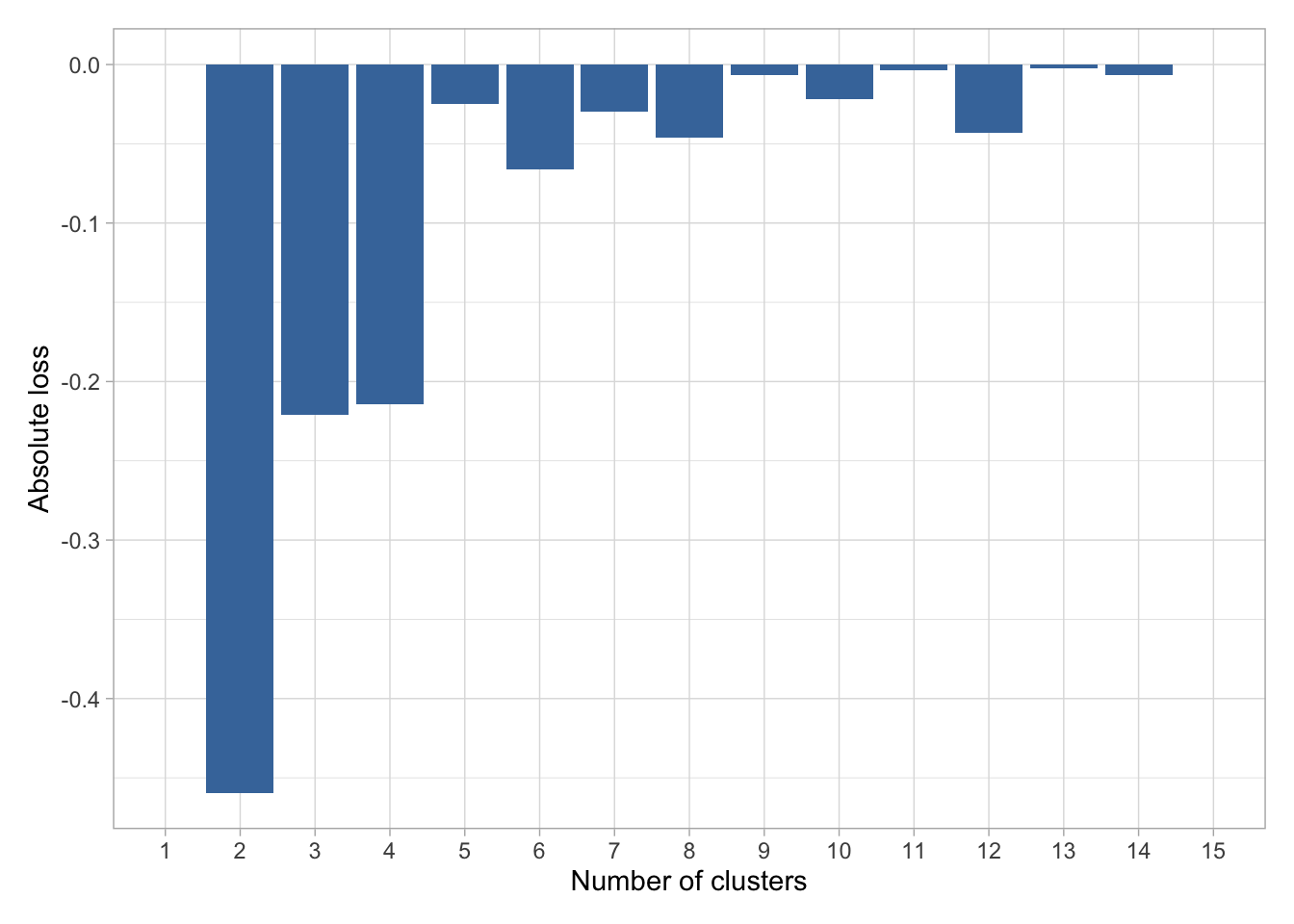
Le nombre idéal de Cluster serait de 3.
Pour confirmer ce choix, nous pouvons utiliser une pour observer les pertes absolue.
cah_fm <- FactoMineR::HCPC(res.pca, graph =FALSE, min =3)cah_fm |>plot_inertia_from_tree()
On remarque que la perte absolue est quasiment équivalente entre un nombre de cluster de 3 ou 4 (si on exclus le fait d’avoir que 2 clusters).
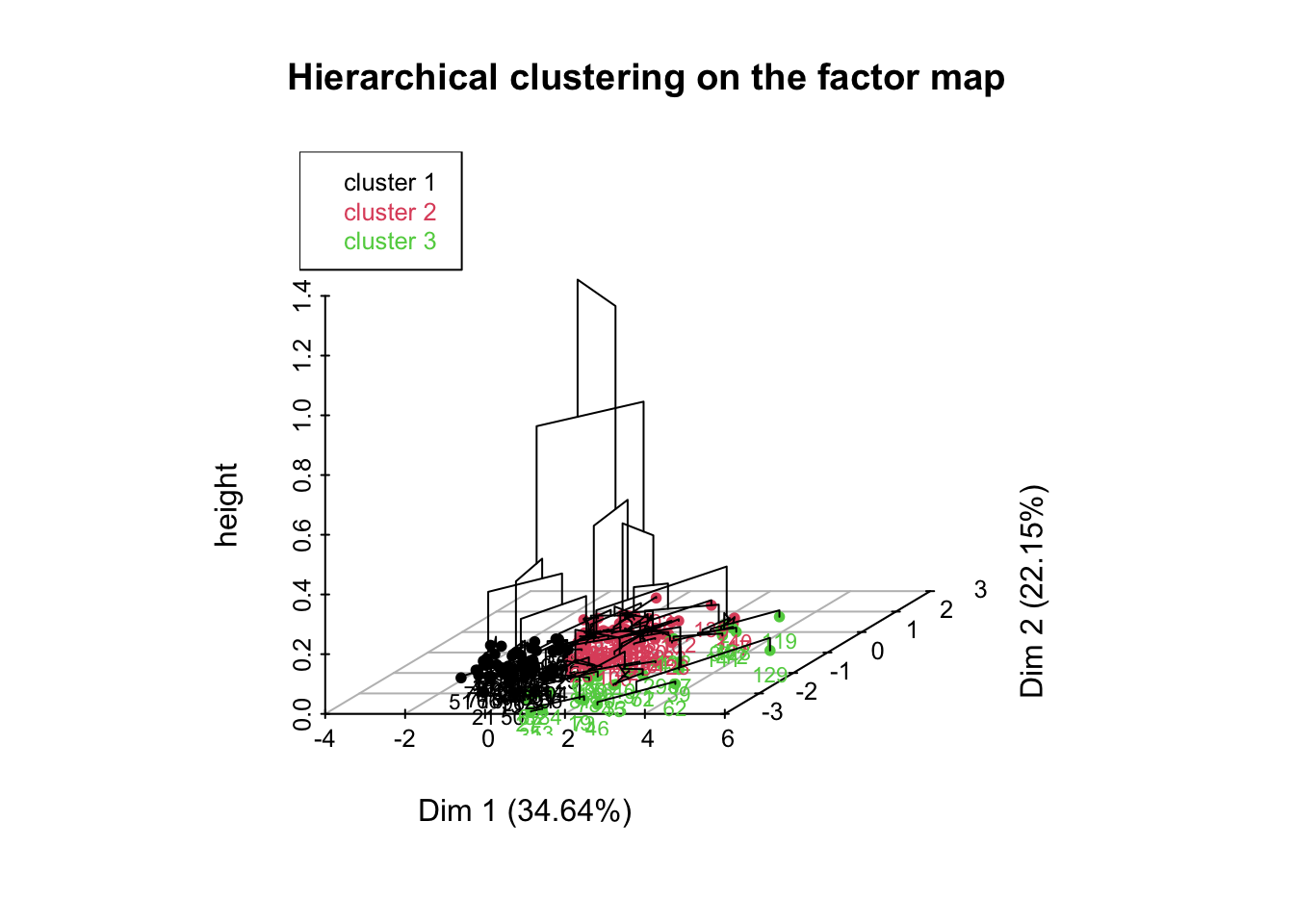
La répartition de cluster est globalement homogène, on observe 3 groupes. Le premiers est situé exclusivement dans la partie gauche avec un majorité dans le cadran inférieur (cluster 1). Le groupe suivant est très concentré dans la partie supérieur gauche avec également des individus présent dans le cadre supérieur droit (cluster 2). Le derniers cluster (3) est moins concentré et présente également moins d’individus, cependant, l’exclusivité des individus sont présent dans la partie droite, avec une majorité dans le cadre inférieur droite.
3. Caractérisation de la typologie
Pour favorisé la caractérisation, on utilise un score de sportivité basé sur les variables de marche et d’activité physique modérée et intense. Comme le temps assis mesure préférentiellement la sédentarité, il n’est pas pris en compte dans le calcul de se score
# Supposons que vos données s'appellent 'data'# Standardisation des variables d'activité physiquedata_standardized <- d1 %>%mutate(TempsAssis_z =scale(TempsAssis), # Standardisation du TempsAssisMarcheMET_z =scale(MarcheMET), # Standardisation du MarcheMETModereeMET_z =scale(ModéréeMET), # Standardisation du ModéréeMETIntensiteMET_z =scale(IntensitéMET) # Standardisation du IntensitéMET )# Inversion de la variable TempsAssis_z car elle diminue le scoredata_standardized <- data_standardized %>%mutate(TempsAssis_inv =-TempsAssis_z)# Création du score de sportivitédata_standardized <- data_standardized %>%mutate(Score_Sportivite = MarcheMET_z + ModereeMET_z + IntensiteMET_z )# Calcul de la moyenne des scores par groupescore_par_groupe <- data_standardized %>%group_by(typo_cah_fm) %>%summarise(Moyenne_Score =mean(Score_Sportivite, na.rm =TRUE))# Affichage du score par groupeprint(score_par_groupe)
d1 <- d1 %>%mutate(TempsAssis_z =scale(TempsAssis), # Standardisation du TempsAssisMarcheMET_z =scale(MarcheMET), # Standardisation du MarcheMETModereeMET_z =scale(ModéréeMET), # Standardisation du ModéréeMETIntensiteMET_z =scale(IntensitéMET), # Standardisation du IntensitéMETTempsAssis_inv =-TempsAssis_z, # Inversion du TempsAssis standardiséScore_Sportivite = TempsAssis_inv + MarcheMET_z + ModereeMET_z + IntensiteMET_z # Calcul du score )# Suppression des colonnes intermédiaires (si elles ne sont plus nécessaires)d1 <- d1 %>%select(-TempsAssis_z, -MarcheMET_z, -ModereeMET_z, -IntensiteMET_z, -TempsAssis_inv)
Characteristic
1, N = 541
2, N = 551
3, N = 371
Score.fertilité
0.43 (0.36, 0.53)
0.58 (0.47, 0.63)
0.43 (0.35, 0.54)
TempsAssis
360 (195, 480)
360 (240, 458)
240 (120, 300)
MarcheMET
495 (265, 660)
330 (165, 660)
990 (248, 1,980)
ModéréeMET
0 (0, 1,150)
800 (0, 1,200)
6,000 (3,600, 6,000)
IntensitéMET
0 (0, 0)
3,200 (2,400, 4,800)
0 (0, 4,800)
TotalMET
990 (330, 2,498)
4,800 (3,600, 5,654)
9,330 (5,625, 10,965)
Fertile
Non
34 (63%)
16 (29%)
23 (62%)
Oui
20 (37%)
39 (71%)
14 (38%)
Score_Sportivite
-1.60 (-2.53, -0.76)
-0.32 (-1.13, 1.02)
2.03 (1.44, 3.47)
1 Median (IQR); n (%)
Dans le détail de nos cluster, on retrouve bien le cluster 3 en sous effectifs par rapport au deux autres. Le 2ème cluster présente un score IA supérieur et une activité physique situé entre le cluster 1 et 3. Ces 2 autres cluster présentent le même score d’IA mais une activité physique et une sédentarité différente. En effet, le cluster 1 présente une sédentarités plus élevé et une activité physique plus faible, contrairement au cluster 3 qui à une activité physique plus élevé et une sédentarité plus faible. La où le cluster 2 est représenté majoritairement par des individus fertile, les cluster 1 et 3 semblent identiques dans leur répartition alors qu’il ne disposent pas des mêmes données d’activité physique et semblent tendre vers une infertilité.
Test de l’indépendance des cluster
On créer des subset des cluster via les jeu de donnée d1
Hypothèse H0 : les clusters selon le score de fertilité suivent une distribution de loi normal
Voir le code
#Test de Shapiroshapiro_Cluster1=shapiro.test(Cluster1$Score.fertilité)shapiro_Cluster2=shapiro.test(Cluster2$Score.fertilité)shapiro_Cluster3=shapiro.test(Cluster3$Score.fertilité)shapiro_Cluster1a=shapiro.test(Cluster1$TempsAssis)shapiro_Cluster1b=shapiro.test(Cluster2$TempsAssis)shapiro_Cluster1c=shapiro.test(Cluster3$TempsAssis)shapiro_Cluster2a=shapiro.test(Cluster1$Score_Sportivite)shapiro_Cluster2c=shapiro.test(Cluster2$Score_Sportivite)shapiro_Cluster2b=shapiro.test(Cluster3$Score_Sportivite)#Réorganisation des data_framed3 <-data.frame(valeurs =c(Cluster1$Score.fertilité, Cluster2$Score.fertilité, Cluster3$Score.fertilité),groupe =factor(rep(c("Groupe 1", "Groupe 2", "Groupe 3"), times =c(length(Cluster1$Score.fertilité), length(Cluster2$Score.fertilité), length(Cluster3$Score.fertilité)))))d4 <-data.frame(valeurs =c(Cluster1$TempsAssis, Cluster2$TempsAssis, Cluster3$TempsAssis),groupe =factor(rep(c("Groupe 1", "Groupe 2", "Groupe 3"), times =c(length(Cluster1$TempsAssis), length(Cluster2$TempsAssis), length(Cluster3$TempsAssis)))))d18 <-data.frame(valeurs =c(Cluster1$Score_Sportivite, Cluster2$Score_Sportivite, Cluster3$Score_Sportivite),groupe =factor(rep(c("Groupe 1", "Groupe 2", "Groupe 3"), times =c(length(Cluster1$Score_Sportivite), length(Cluster2$Score_Sportivite), length(Cluster3$Score_Sportivite)))))#Test ANOVAanova_resultat <-aov(valeurs ~ groupe, data = d3)anova_resultat2 <-aov(valeurs ~ groupe, data = d4)anova_resultat3 <-aov(valeurs ~ groupe, data = d18)#Graphique pour le score de fertilitép4 <-ggplot(d3, aes(x = valeurs, fill = groupe)) +geom_density(alpha =0.5) +stat_function(fun = dnorm, args =list(mean =mean(d3$valeurs), sd =sd(d3$valeurs)), color ="black", size =1, linetype ="dashed") +# Courbe normalelabs(title ="Courbes de densité des distributions avec courbe normale pour le score", x ="Valeurs", y ="Densité") +theme_minimal() +theme(legend.position ="top")p4 <- p4 +annotate("text", x =Inf, y =Inf, label =paste("Shapiro-Wilk:\nCluster1: W =", round(shapiro_Cluster1$statistic, 4), ", p =", round(shapiro_Cluster1$p.value, 4), "\nCluster2: W =", round(shapiro_Cluster2$statistic, 4), ", p =", round(shapiro_Cluster2$p.value, 4),"\nCluster2: W =", round(shapiro_Cluster3$statistic, 4),", p =", round(shapiro_Cluster3$p.value, 4)),hjust =1.1, vjust =1.5, size =2.5, color ="black", parse =FALSE)#Graphique pour le temps assisp5 <-ggplot(d4, aes(x = valeurs, fill = groupe)) +geom_density(alpha =0.5) +stat_function(fun = dnorm, args =list(mean =mean(d4$valeurs), sd =sd(d4$valeurs)), color ="black", size =1, linetype ="dashed") +# Courbe normalelabs(title ="Courbes de densité des distributions avec courbe normale pour le temps assis", x ="Valeurs", y ="Densité") +theme_minimal() +theme(legend.position ="top")p5 <- p5 +annotate("text", x =Inf, y =Inf, label =paste("Shapiro-Wilk:\nCluster1: W =", round(shapiro_Cluster1a$statistic, 4), ", p =", round(shapiro_Cluster1a$p.value, 4), "\nCluster2: W =", round(shapiro_Cluster1b$statistic, 4), ", p =", round(shapiro_Cluster1b$p.value, 4),"\nCluster2: W =", round(shapiro_Cluster1c$statistic, 4),", p =", round(shapiro_Cluster1c$p.value, 4)),hjust =1.1, vjust =1.5, size =2.5, color ="black", parse =FALSE)#Graphique pour le score de sportivitép18 <-ggplot(d18, aes(x = valeurs, fill = groupe)) +geom_density(alpha =0.5) +stat_function(fun = dnorm, args =list(mean =mean(d18$valeurs), sd =sd(d18$valeurs)), color ="black", size =1, linetype ="dashed") +# Courbe normalelabs(title ="Courbes de densité des distributions avec courbe normale pour le score de sportivité", x ="Valeurs", y ="Densité") +theme_minimal() +theme(legend.position ="top")p18 <- p18 +annotate("text", x =Inf, y =Inf, label =paste("Shapiro-Wilk:\nCluster1: W =", round(shapiro_Cluster1a$statistic, 4), ", p =", round(shapiro_Cluster2a$p.value, 4), "\nCluster2: W =", round(shapiro_Cluster1b$statistic, 4), ", p =", round(shapiro_Cluster2c$p.value, 4),"\nCluster2: W =", round(shapiro_Cluster1c$statistic, 4),", p =", round(shapiro_Cluster2b$p.value, 4)),hjust =1.1, vjust =1.5, size =2.5, color ="black", parse =FALSE)
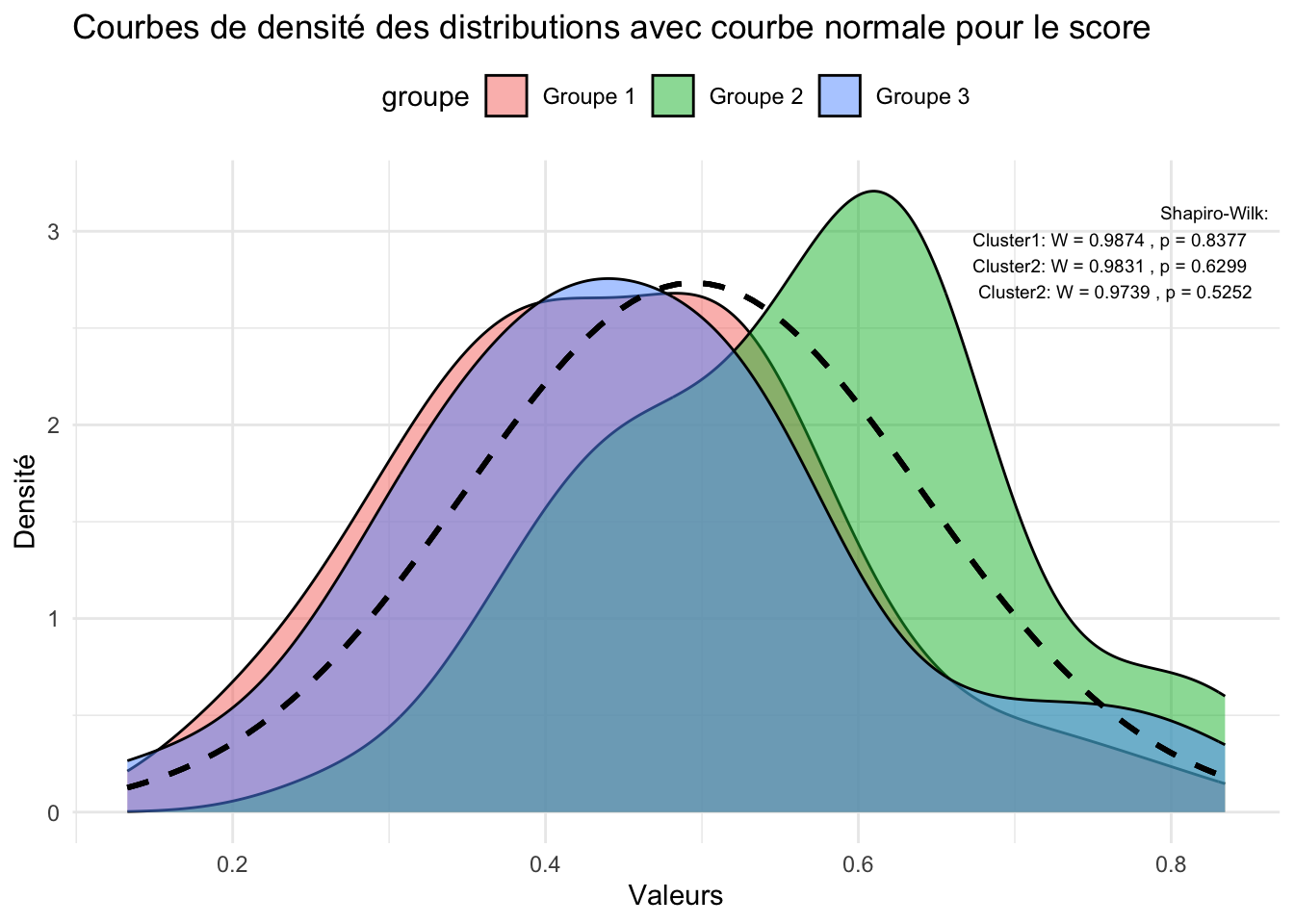
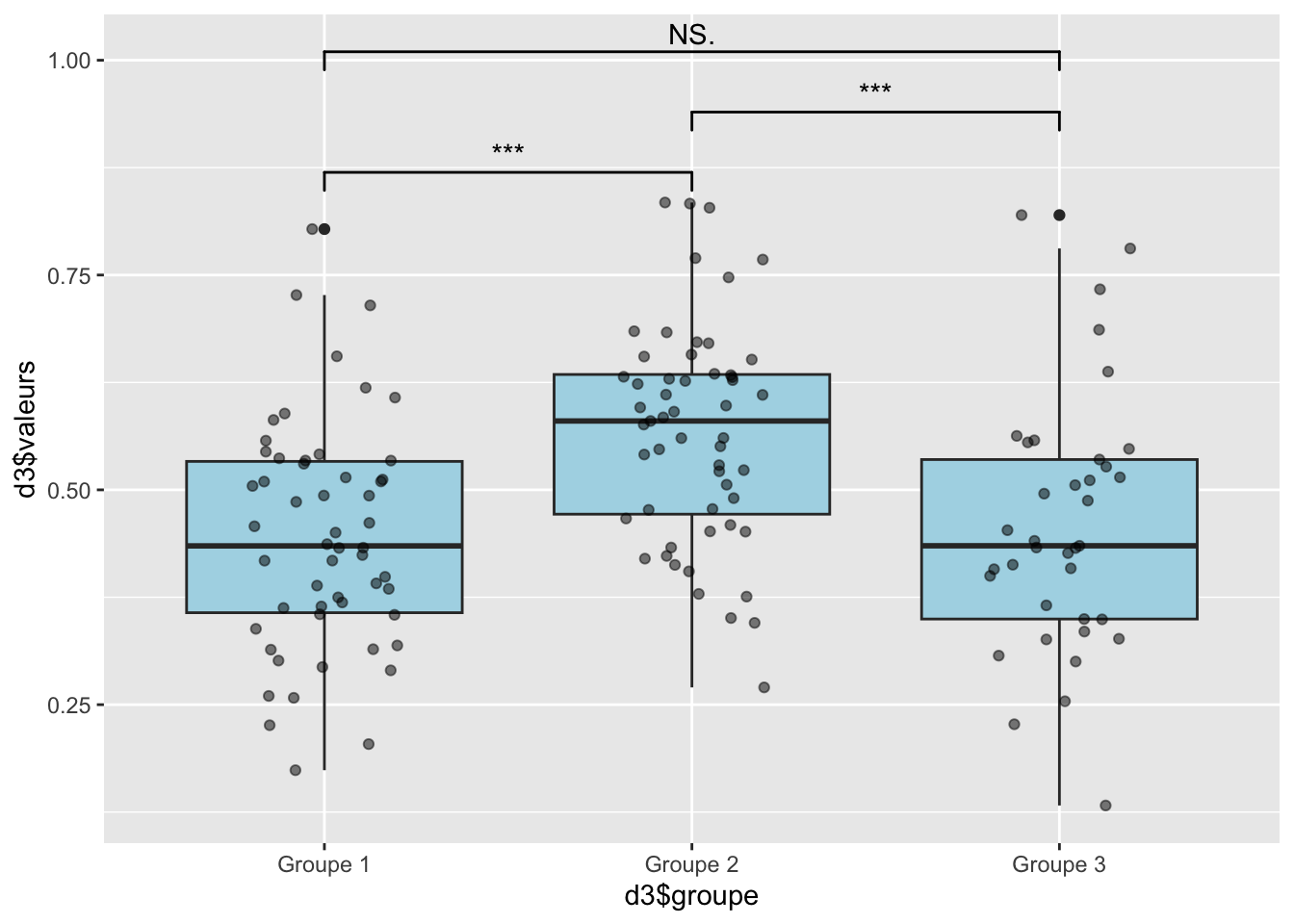
L’ensemble des p-value sont supérieurs à 0,05, on accepte H0 et donc la normalité des distributions pour l’ensemble des clusters représenté par le score de fertilité.
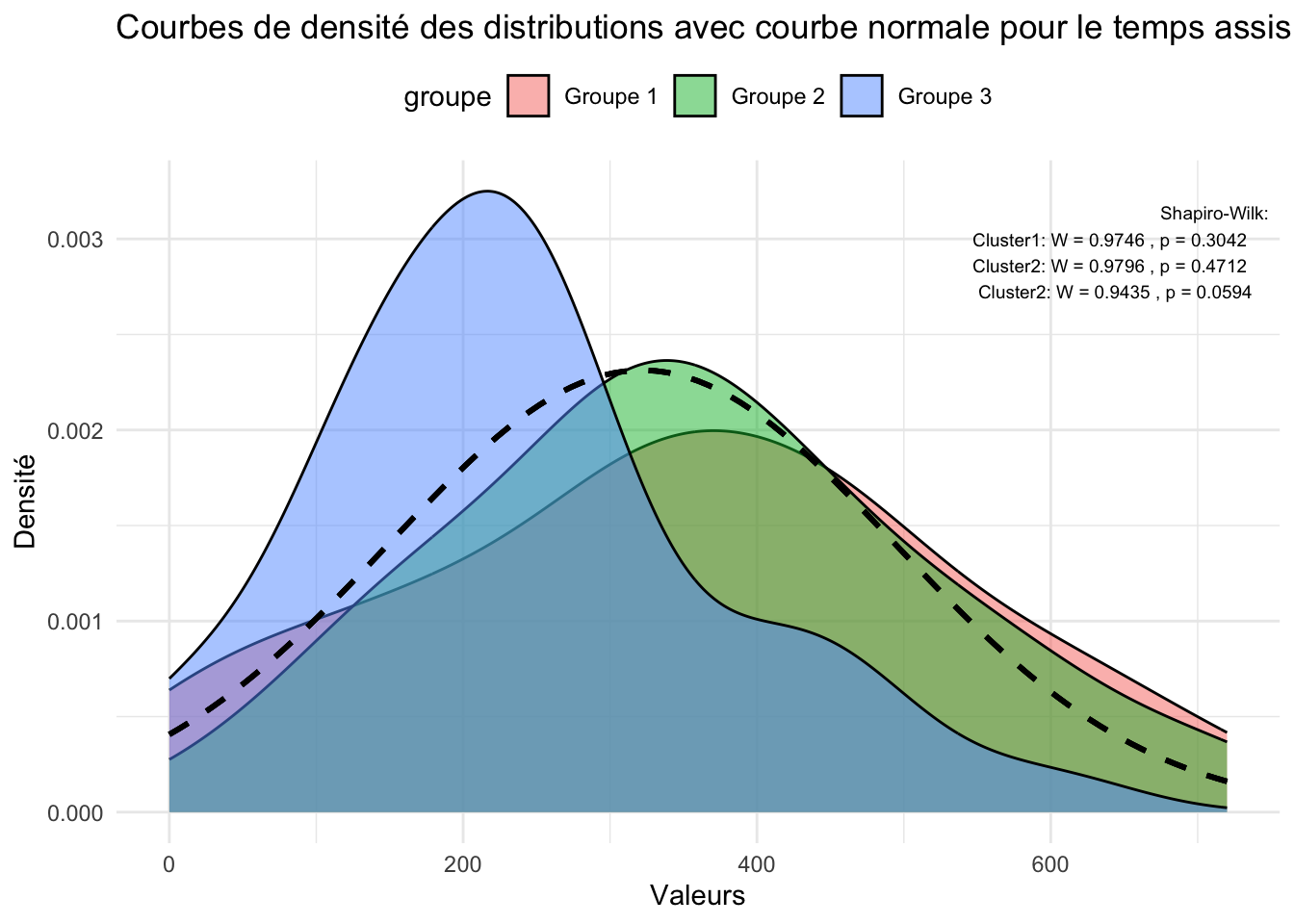
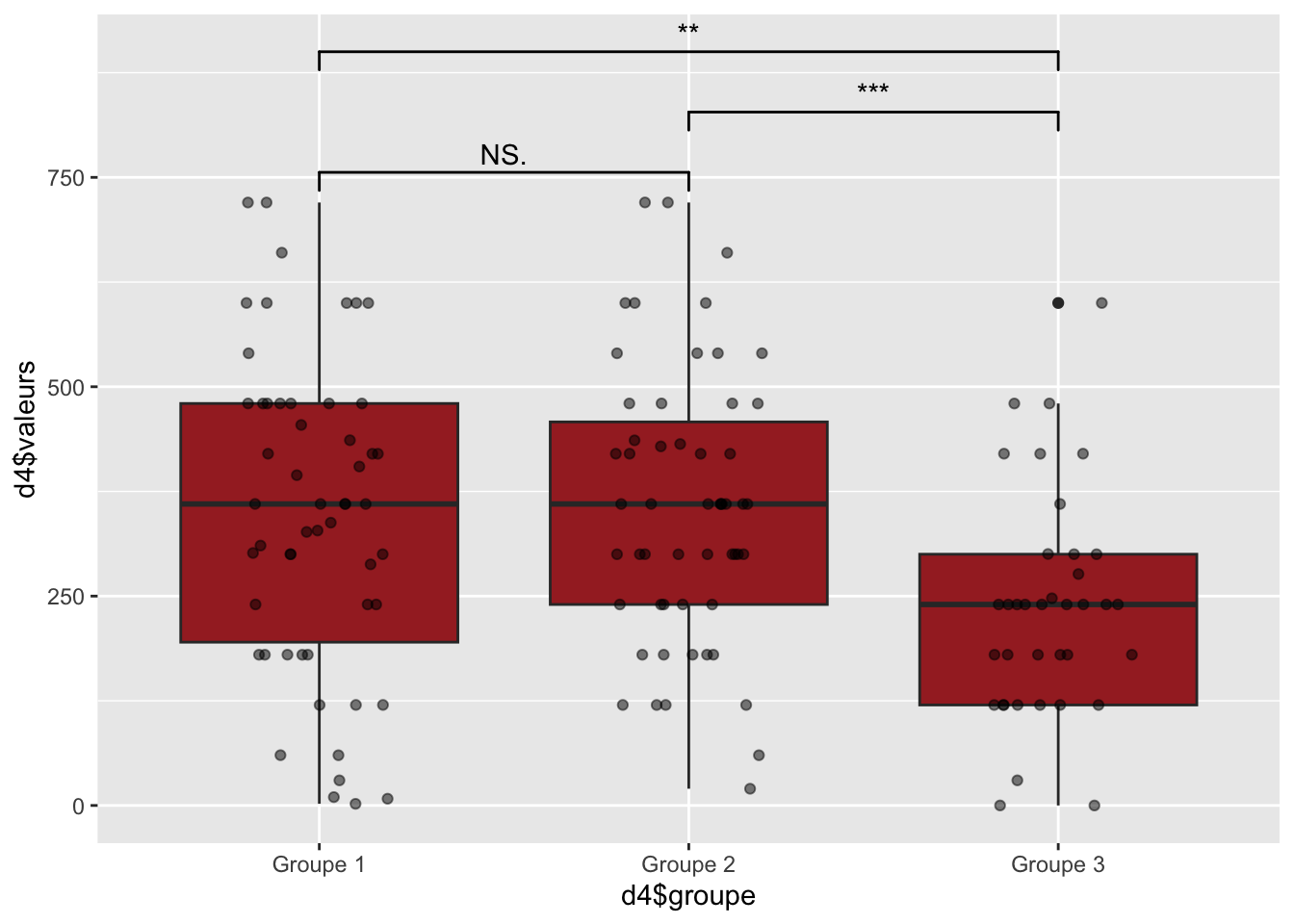
Un fait intéressant est que nous avons également testé la normalité de distribution sur l’ensemble des autres variables (non montré ici). Le score de shapiro pour le temps assis a été de 0,30 / 0,47 / 0,059 pour le cluster 1, 2 et 3 respectivement. Ce nouveau paramètre pourrait éventuellement distinguer le groupe 1 et 3 qui semblait avoir les mêmes paramètres. Un deuxième test ANOVA à donc été calculé
Hypothèse H0 : Les moyennes des scores de fertilité et du temps assis des 3 groupes ne sont pas significativement différentes.
summary(anova_resultat)
Df Sum Sq Mean Sq F value Pr(>F)
groupe 2 0.4621 0.23107 12.58 9.24e-06 ***
Residuals 143 2.6257 0.01836
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
summary(anova_resultat2)
Df Sum Sq Mean Sq F value Pr(>F)
groupe 2 370211 185106 6.71 0.00164 **
Residuals 143 3944824 27586
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
summary(anova_resultat3)
Df Sum Sq Mean Sq F value Pr(>F)
groupe 2 377.0 188.52 79.65 <2e-16 ***
Residuals 143 338.5 2.37
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Résultat des ANOVA
On rejette l’hypothèse nul pour les 2 variables. Pour le score de fertilité et le temps assis, il y a une différence significative
On observe bien que le groupe 2 est statistiquement différent du groupe 1 et 3. Ce qui fait de lui, le groupe avec un score de fertilité plus élevé. Le groupe 1 et 3 n’étant pas statistiquement différent. Cependant, le temps assis est une variable à distribution normal et elle montre une différence significative du groupe 3 qui présente une temps assis inférieur au groupe 2 et 1, là ou ces 2 derniers semblent identiques.
Analyse des autres variables par test non paramétrique
Hormis le score de fertilité et le temps assis, toutes les autres variables ne suivent pas une loi normal. Pour pouvoir tout de même ajuster le discours, on utilise la variante non paramétrique du test d’ANOVA : le test de Kurskall Wallis, le test de post HOC est le test de dunn.
Voir le code
d5=d1[,c(1,2,3,4,5,6,7)]names(d1)[names(d1) =="typo_cah_fm"] <-"Cluster"d1_normalized <- d1 %>%mutate(across(where(is.numeric), ~ (.-mean(.)) /sd(.)))d5_normalized <- d5 %>%mutate(across(where(is.numeric), ~ (.-mean(.)) /sd(.)))names(d5_normalized)[names(d5_normalized) =="typo_cah_fm"] <-"Cluster"# Convertir Cluster en facteurd5_normalized$Cluster <-as.factor(d5_normalized$Cluster)# Calculer les moyennes par clustermean_data <- d5_normalized %>%group_by(Cluster) %>%summarise(across(where(is.numeric), mean))# Tester la significativité des moyennes pour chaque variable avec Kruskal-Wallis et le test de Dunnanova_results <-lapply(names(mean_data)[-1], function(var) { formula <-as.formula(paste(var, "~ Cluster")) kw_result <-kruskal.test(formula, data = d5_normalized) tidy_result <-tidy(kw_result)# Si Kruskal-Wallis est significatif, faire un test de Dunnif (tidy_result$p.value[1] <0.05) { dunn_result <-dunn.test(d5_normalized[[var]], d5_normalized$Cluster, method ="bonferroni") dunn_df <-data.frame(comparison = dunn_result$comparisons,p_value = dunn_result$P.adjusted,Variable = var )return(dunn_df) } else {return(NULL) }})
Kruskal-Wallis rank sum test
data: x and group
Kruskal-Wallis chi-squared = 23.6637, df = 2, p-value = 0
Comparison of x by group
(Bonferroni)
Col Mean-|
Row Mean | 1 2
---------+----------------------
2 | -4.502158
| 0.0000*
|
3 | -0.396721 3.658235
| 1.0000 0.0004*
alpha = 0.05
Reject Ho if p <= alpha/2
Kruskal-Wallis rank sum test
data: x and group
Kruskal-Wallis chi-squared = 13.7853, df = 2, p-value = 0
Comparison of x by group
(Bonferroni)
Col Mean-|
Row Mean | 1 2
---------+----------------------
2 | -0.212450
| 1.0000
|
3 | 3.208491 3.411834
| 0.0020* 0.0010*
alpha = 0.05
Reject Ho if p <= alpha/2
Kruskal-Wallis rank sum test
data: x and group
Kruskal-Wallis chi-squared = 9.2623, df = 2, p-value = 0.01
Comparison of x by group
(Bonferroni)
Col Mean-|
Row Mean | 1 2
---------+----------------------
2 | 0.975820
| 0.4937
|
3 | -2.128059 -3.015179
| 0.0500 0.0039*
alpha = 0.05
Reject Ho if p <= alpha/2
Kruskal-Wallis rank sum test
data: x and group
Kruskal-Wallis chi-squared = 69.4611, df = 2, p-value = 0
Comparison of x by group
(Bonferroni)
Col Mean-|
Row Mean | 1 2
---------+----------------------
2 | -1.576873
| 0.1722
|
3 | -8.010401 -6.619416
| 0.0000* 0.0000*
alpha = 0.05
Reject Ho if p <= alpha/2
Kruskal-Wallis rank sum test
data: x and group
Kruskal-Wallis chi-squared = 74.1064, df = 2, p-value = 0
Comparison of x by group
(Bonferroni)
Col Mean-|
Row Mean | 1 2
---------+----------------------
2 | -8.579868
| 0.0000*
|
3 | -3.260713 4.457601
| 0.0017* 0.0000*
alpha = 0.05
Reject Ho if p <= alpha/2
Kruskal-Wallis rank sum test
data: x and group
Kruskal-Wallis chi-squared = 104.5757, df = 2, p-value = 0
Comparison of x by group
(Bonferroni)
Col Mean-|
Row Mean | 1 2
---------+----------------------
2 | -6.915395
| 0.0000*
|
3 | -9.848669 -3.654526
| 0.0000* 0.0004*
alpha = 0.05
Reject Ho if p <= alpha/2
# Combiner les résultats de Dunndunn_results_df <-bind_rows(anova_results)# Préparer les données pour le diagramme en boîted5_normalized_long <- d5_normalized %>%pivot_longer(cols =-Cluster, names_to ="Variable", values_to ="Valeur")
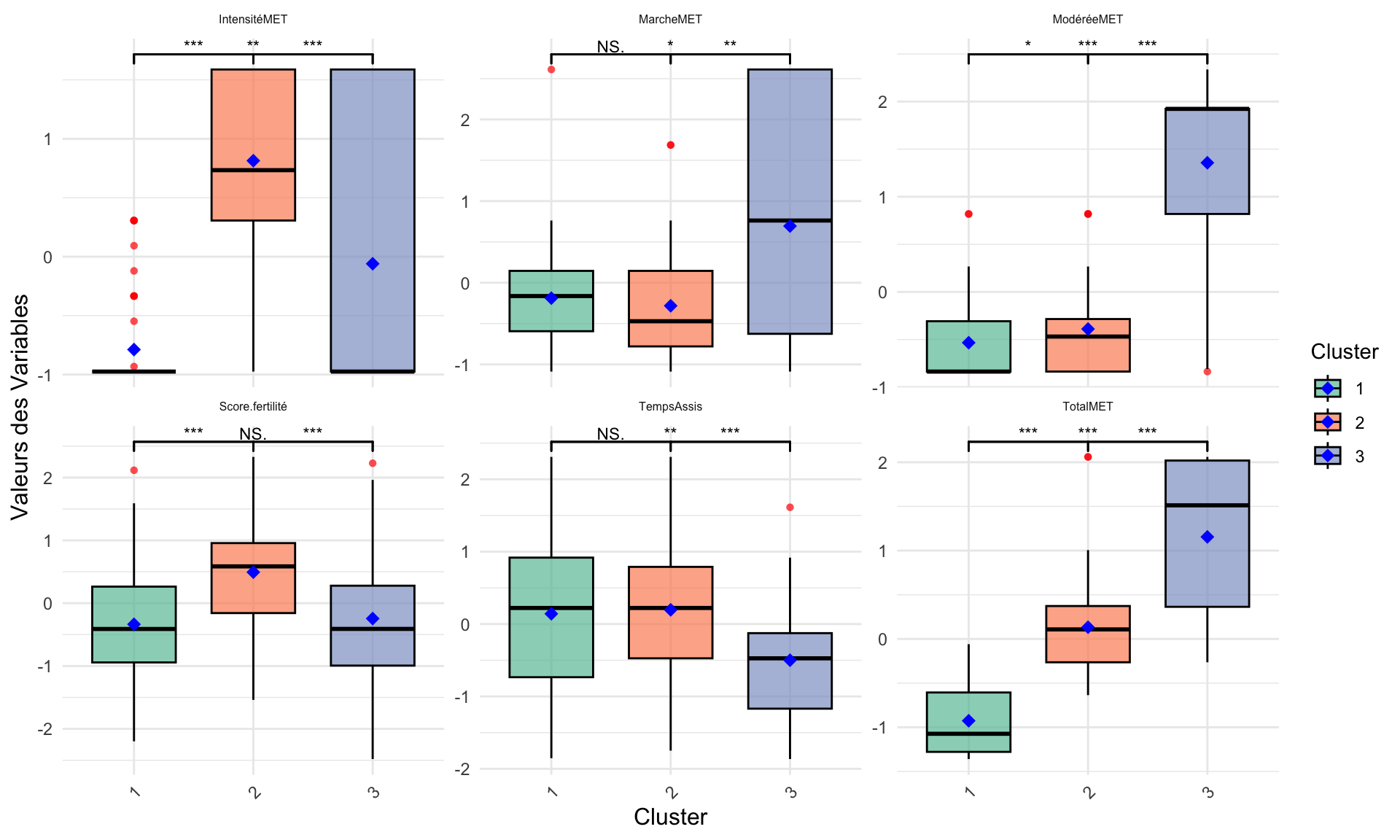
On observe bien que le groupe 2 est statistiquement différent du groupe 1 et 3. Ce qui fait de lui, le groupe avec un score de fertilité plus élevé. Le groupe 1 et 3 n’étant pas statistiquement différent. Cependant, le temps assis est une variable à distribution normal et elle montre une différence significative du groupe 3 qui présente une temps assis inférieur au groupe 2 et 1, là ou ces 2 derniers semblent identiques. Si on observe les autres variables, on remarque que il n’y a que la marche entre le groupe 1 et 2 qui est non significative.
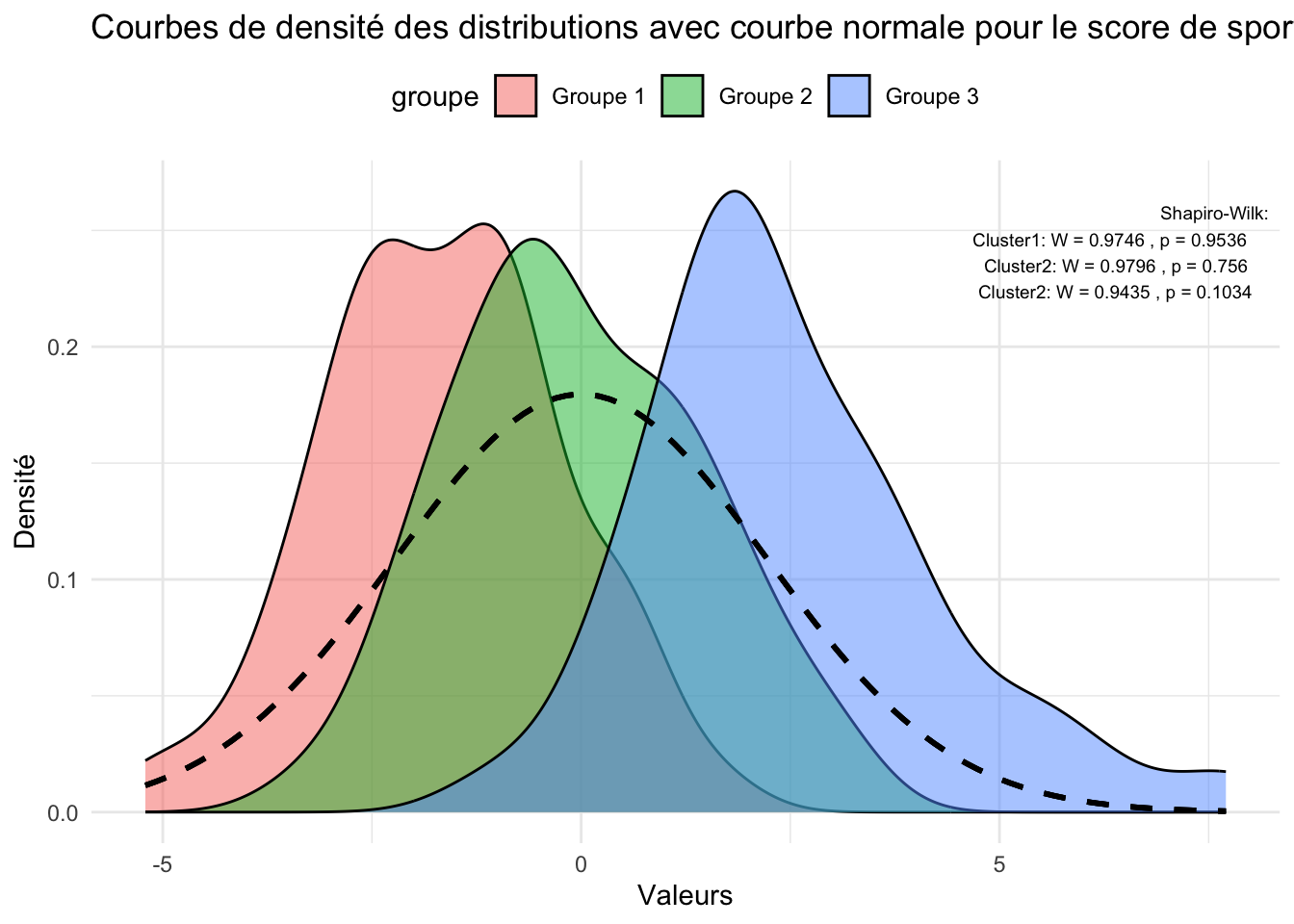
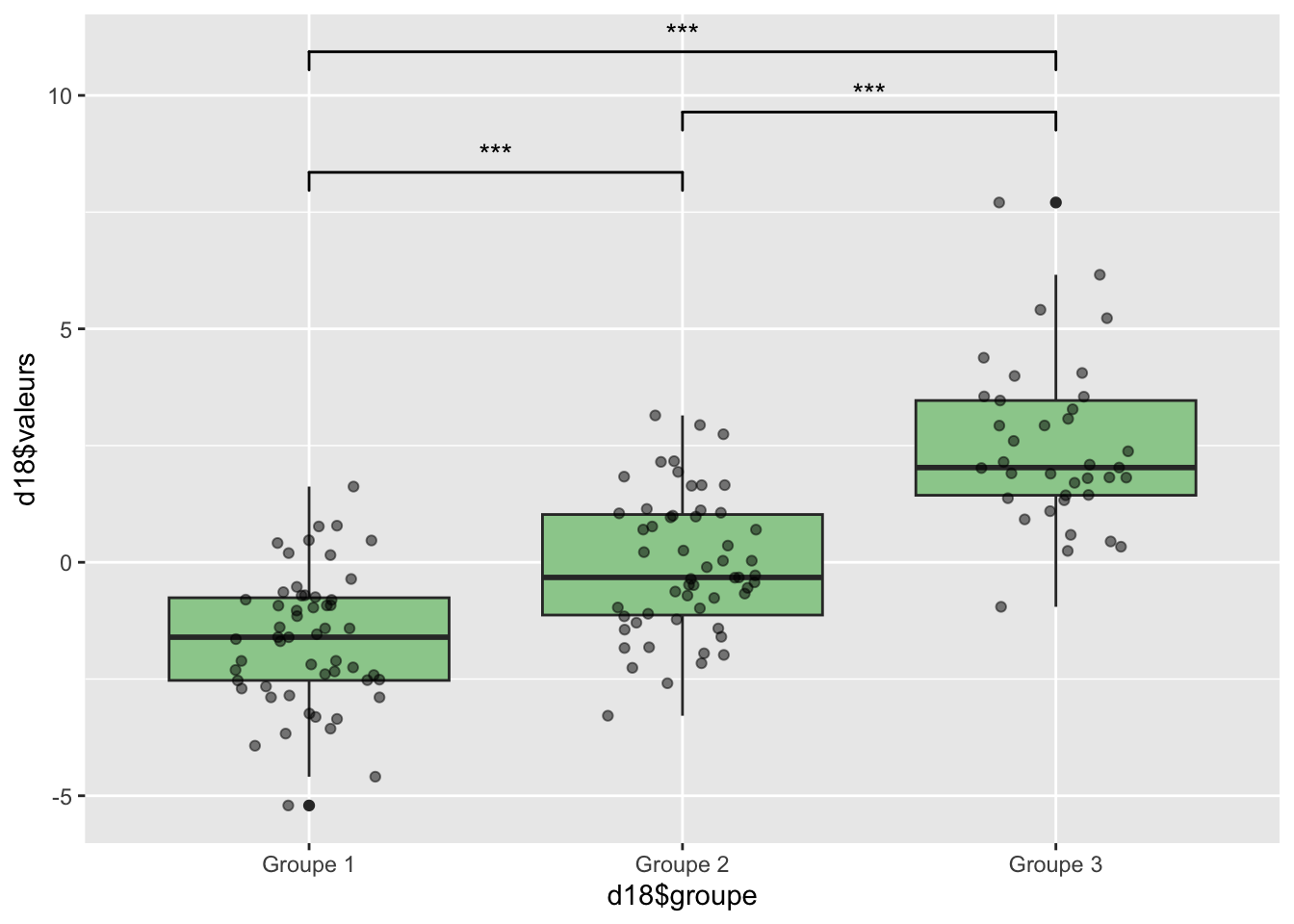
Au final si on devait établir des profils de sportivité au différent cluster, on admettra que le cluster 1 est composé d’individus peut sportif et sédentaire. Concernant le groupe 2 et 3, on remarque que le groupe 3 est légèrement supérieur en terme de profil sportif à la différence qu’il a moins d’individus avec une activité physique intense mais qui est contrebalancé par l’activité total qui est supérieur. La différence entre le groupe 2 et 3 est dû au score de fertilité qui est plus important pour le groupe 2.
4. Projection sur la fertilité
Pour finir l’analyse des clusters, on peut les projeters sur la fertilité pour comparer les groupes.
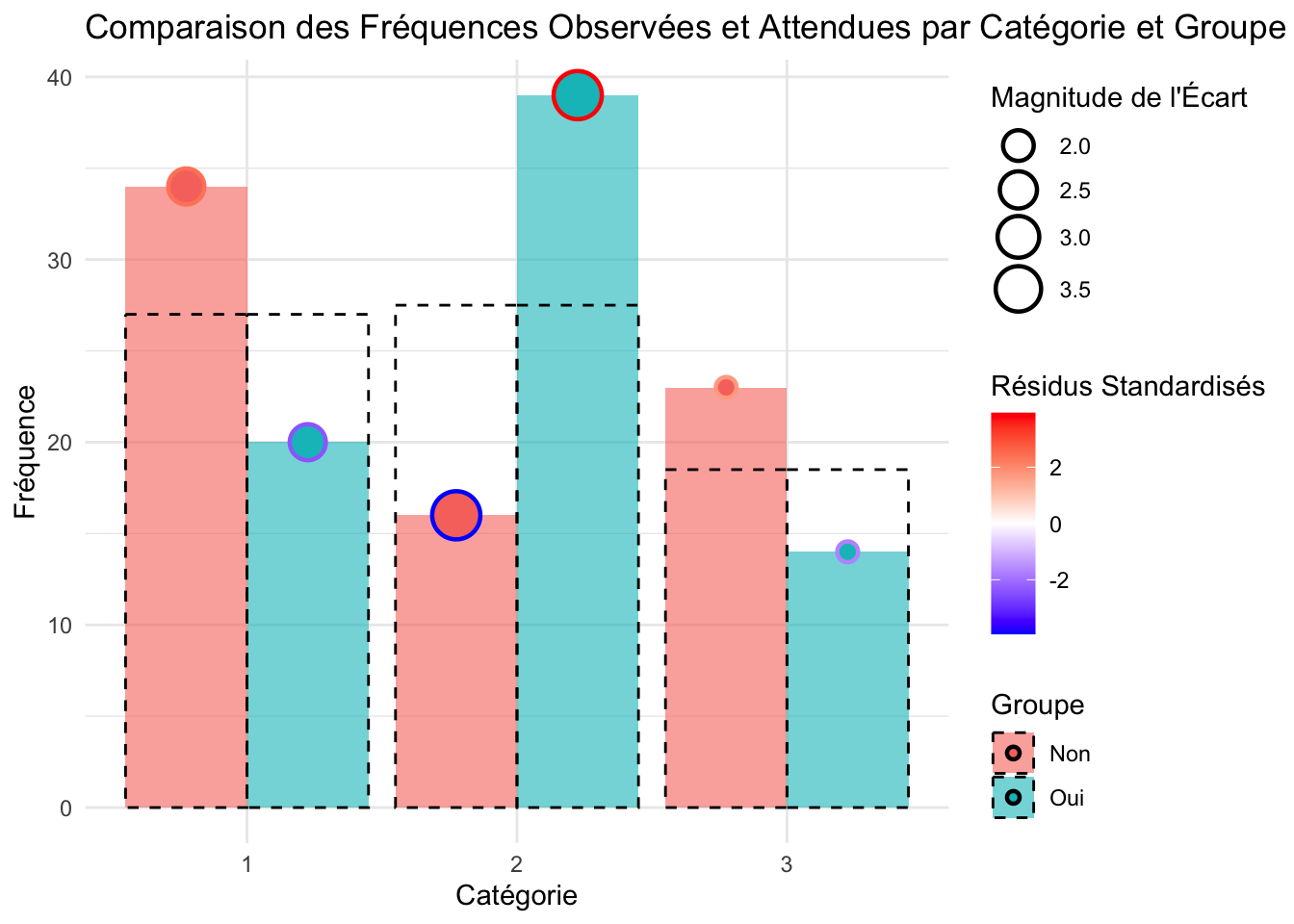
tabCont22 <-xtabs(~Fertile+d1$Cluster,data=d1)
Un test de Chi2 est réalisé
H0 : Il y a indépendance entre les variables qualitatives A et B.
X-squared
15.437
La majorité des individues fertiles sont issus du groupes 2. Le groupe 2 et 3 semblent confirmer la même tendance avec une majorité d’individus infertile, de plus, le rapport entre fertile et infertile est quasiment le même. La différence entre les fréquences attendu et observé sont bien visible sur le graphique. Avec un X obs de 15,437. On peut rejeté l’hypothèse H0 et conclure que les variables sont dépendantes. Il y a bien un lien entre les clusters et la fertilité.
5. Conclusion
Le score de Hopkins confirme une analyse en clustering potentiellement efficace. Ce clustering se divisera en 3 groupes comme suggéré par l’extension JLutils. Le but du clustering est de réalisé dans la suite, une analyse en classification ascendante hiérarchique. Graphiquement, on observe 3 groupes distincts. Le cluster 2 semblent bien supérieur dans leur score (0,58) contrairement au cluster 1 et 3. Ces 2 derniers tende à se distinguer par un profil sportif différent. Pour mieux caractériser ce profil de sportivité, un petit algorithme de création de score sur les variables est utilisé. L’indépendance des clusters est observer pour vérifier si ils dépendant bien de variable liées à l’activité physique. Il y a 3 variables qui suivent une loi normal soit la variable du score de fertilité, du temps assis et du score de sportivité. Un test ANOVA est réalisé pour ces 3 variables et un test de Kruskall-Wallis pour les autres ne suivant pas une loi normale. Le score de fertilité est significativement élevé pour le groupe 2 par rapport au groupe 1 et 3 qui possèdent la même homogénéités des valeurs scorique. Concernant l’activité physique, de manière général, le groupe 3 possède un profil significativement plus élevé que le groupe 2 et 1, de même pour le groupe 2 par rapport au groupe 1. Dans l’observation des comparaisons non paramétrique, le groupe 3 se distingue par une activité de marche et modérée significativement plus élevé par rapport au autre groupe. Le groupe 2 quant a lui semble être sauvé par des invidious avec un temps d’activité physique intense plus élevé mais qui ne suffit pas, sur l’activité total, à rattraper le groupe 3. Dans la sédentarité, le groupe 3 possède des individus avec un temps assis significativement plus faible que le groupe 2 et 1 qui possède le même temps. La projection de ses groupes sur la fertilité montre une majorité d’individus fertile dans le groupe 2, là ou le score de fertilité se montre plus élevé mais où l’activité physique semblent également présente. Le groupe 1, qui possède une score de fertilité et un score de sportivité diminué montrent une majorité d’individus infertile, là ou le groupe 3 semble compensé le score de fertilité par un fort score sportivité montrant ainsi une proportion plus élevé d’imdividus fertile.
Partie V : Apprentissage automatique
Parmis les différents, nous avons testé différent modèle de prédiction. Le modèle qui a retenu notre attention était le modèle de forêt aléatoire qui semblait présenter des meilleurs paramètres. Seulement, on peut se rendre compte que l’accurency et le Kappa varie beaucoup lors de la validation croisée. Ce qui justifie que nos données acutelles ne permettent pas de créer un bon modèle de prédiction.
Une application Shiny montre la variation des paramètres selon l’actualisation du graphique