Attaching package: 'reshape2'
The following object is masked from 'package:tidyr':
smiths
library(plotly)
Attaching package: 'plotly'
The following object is masked from 'package:ggplot2':
last_plot
The following object is masked from 'package:stats':
filter
The following object is masked from 'package:graphics':
layout
Attaching package: 'MASS'
The following object is masked from 'package:patchwork':
area
The following object is masked from 'package:plotly':
select
The following object is masked from 'package:dplyr':
select
library(lattice)
Attaching package: 'lattice'
The following object is masked from 'package:boot':
melanoma
library(esquisse)library(testthat)
Attaching package: 'testthat'
The following object is masked from 'package:khroma':
compare
The following object is masked from 'package:dplyr':
matches
The following object is masked from 'package:purrr':
is_null
The following objects are masked from 'package:readr':
edition_get, local_edition
The following object is masked from 'package:tidyr':
matches
library(rsconnect)
Attaching package: 'rsconnect'
The following object is masked from 'package:shiny':
serverInfo
Registered S3 method overwritten by 'quantmod':
method from
as.zoo.data.frame zoo
library(rpart)library(RSEIS)
Attaching package: 'RSEIS'
The following object is masked from 'package:boot':
envelope
library(FactoMineR)library(gtsummary)
Attaching package: 'gtsummary'
The following object is masked from 'package:testthat':
matches
The following object is masked from 'package:MASS':
select
library(corrplot)
corrplot 0.92 loaded
library(devtools)
Loading required package: usethis
Attaching package: 'devtools'
The following object is masked from 'package:rsconnect':
lint
The following object is masked from 'package:testthat':
test_file
library(factoextra)
Welcome! Want to learn more? See two factoextra-related books at https://goo.gl/ve3WBa
library(corrr)library(clusterSim)
Loading required package: cluster
library(DataExplorer)library(caret)
Attaching package: 'caret'
The following objects are masked from 'package:DescTools':
MAE, RMSE
The following object is masked from 'package:purrr':
lift
library(rattle)
Loading required package: bitops
Attaching package: 'bitops'
The following object is masked from 'package:DescTools':
%^%
Rattle: A free graphical interface for data science with R.
Version 5.5.1 Copyright (c) 2006-2021 Togaware Pty Ltd.
Type 'rattle()' to shake, rattle, and roll your data.
library(randomForest)
randomForest 4.7-1.2
Type rfNews() to see new features/changes/bug fixes.
Attaching package: 'randomForest'
The following object is masked from 'package:rattle':
importance
The following object is masked from 'package:dplyr':
combine
The following object is masked from 'package:ggplot2':
margin
library(e1071)library(pROC)
Type 'citation("pROC")' for a citation.
Attaching package: 'pROC'
The following objects are masked from 'package:stats':
cov, smooth, var
library(ggpubr) library(psych)
Attaching package: 'psych'
The following object is masked from 'package:randomForest':
outlier
The following objects are masked from 'package:DescTools':
AUC, ICC, SD
The following object is masked from 'package:testthat':
describe
The following object is masked from 'package:boot':
logit
The following objects are masked from 'package:ggplot2':
%+%, alpha
library(knitr)library(gridExtra)
Attaching package: 'gridExtra'
The following object is masked from 'package:randomForest':
combine
The following object is masked from 'package:dplyr':
combine
Notre jeu de donnée APF se composent de 146 observations représentant les 146 femmes répondant à l’étude. Il est inclu 7 variables. Dans le cadre de l’ACP, seul les valeurs quantitatives seront utilisés, pour la suite du traitement on utilisera (d) comme l’ensemble des valeurs quantitatives.
d=APF[,c(1,3,4,5,6,7)]
1. Traitement des valeurs manquantes
nrow(d[!complete.cases(d),])
[1] 30
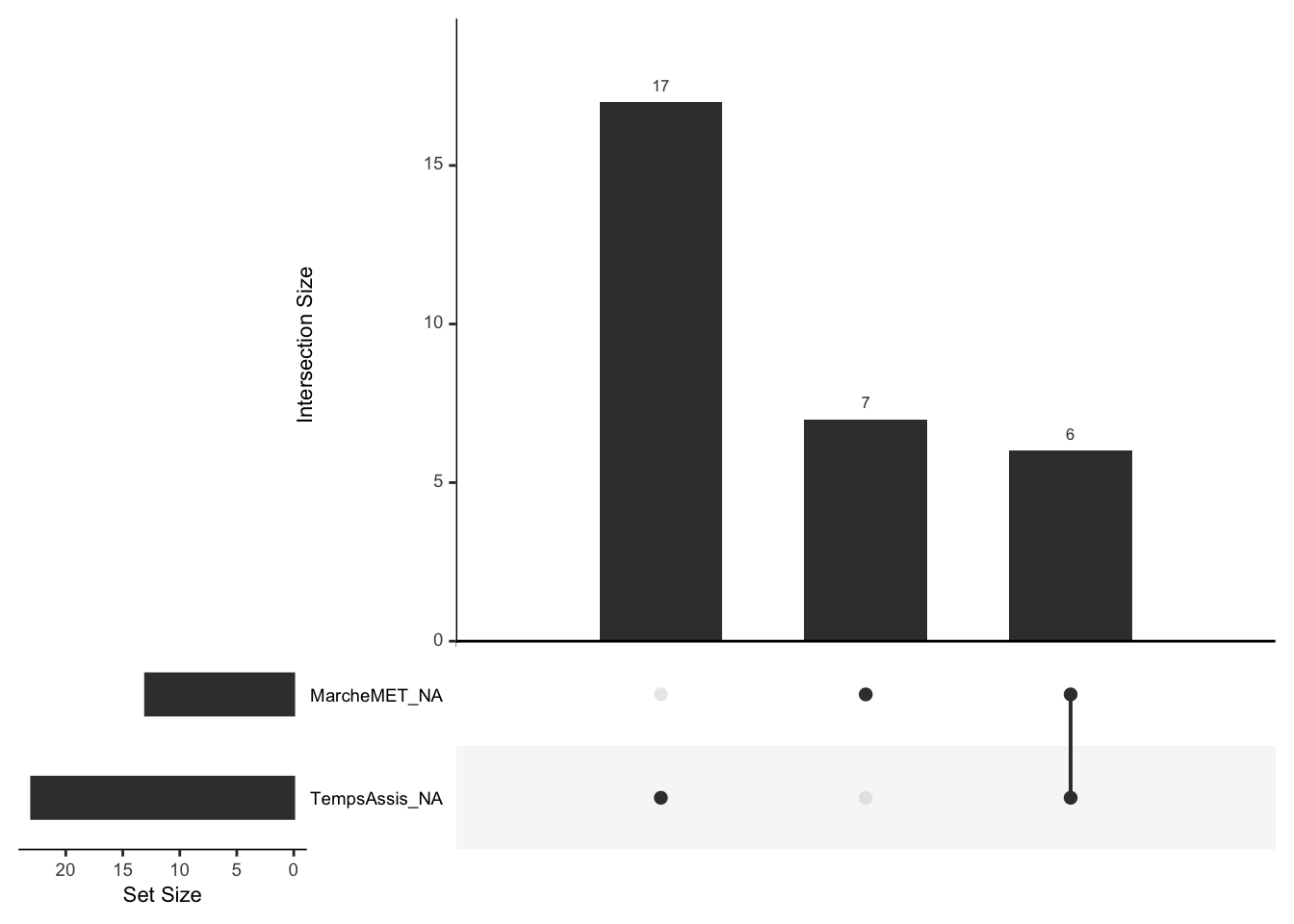
Sur les 146 questionnaires, l’ensemble des données liées à l’activité physique a été rempli. Pour le temps assis, 16 % des valeurs sont manquantes, et 9 % pour la marche, ce qui représente au total 30 valeurs manquantes. Plus précisément, on peut remarquer que 6 des valeurs manquantes sont attribuées à la fois pour le temps assis et pour la marche.
Imputation de données manquantes par les K plus proches voisins
Au vu du faible nombre de donnée, un K trop élevé peut inclure des voisins trop éloignés et diluer la précision de la prédiction. La moyenne pondéré est attribuée à la valeur manquante
d1 <-knnImputation(d, k =7, scale =TRUE, meth ="weighAvg")
2. Traitement des valeurs aberrantes et extrêmes
Une valeurs aberrantes, ou extrême, est une observation distante des autres sur un phénomène semblable. L’argument d’une données issus d’une déclaration est suffisant pour imputer ces valeurs.
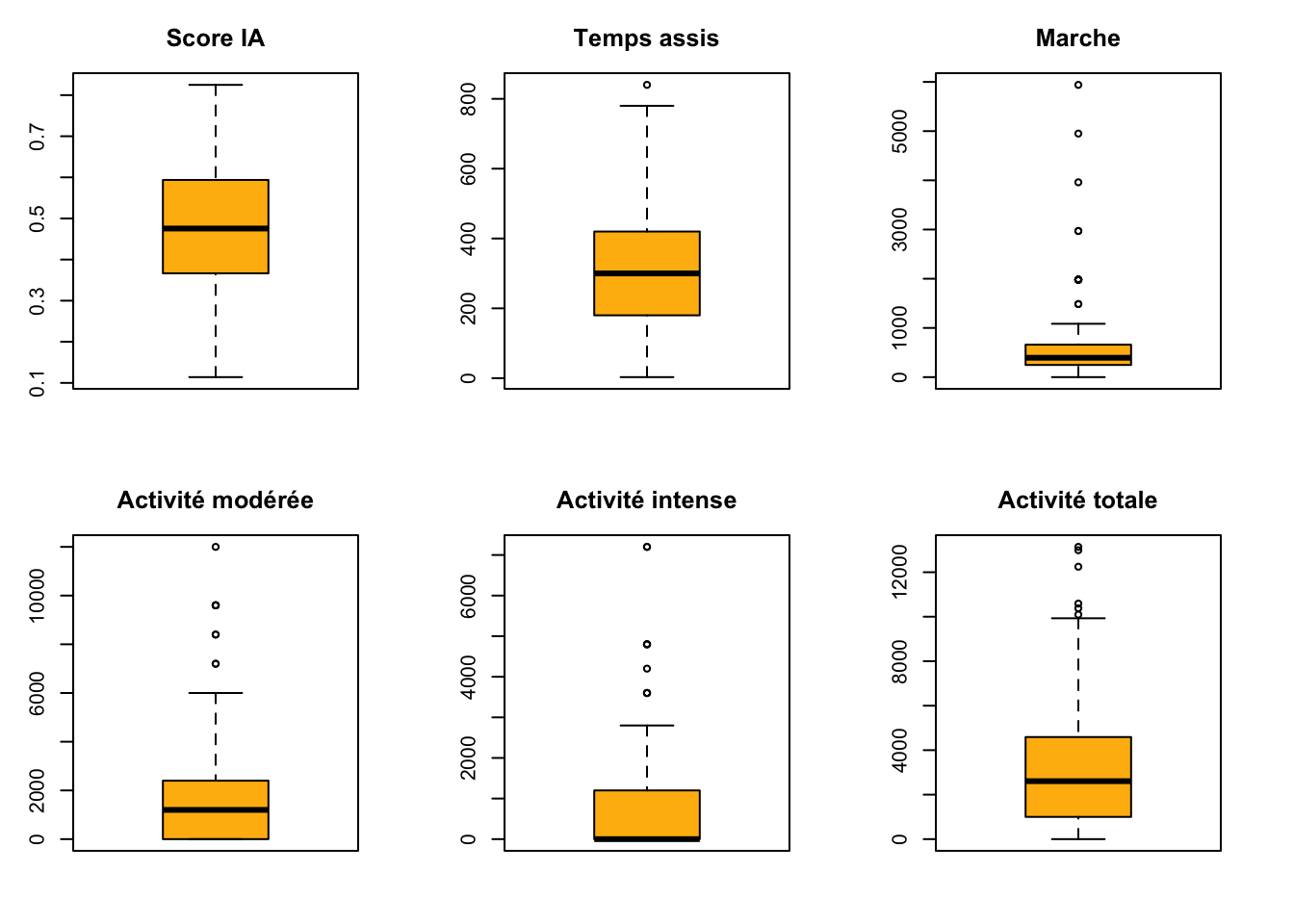
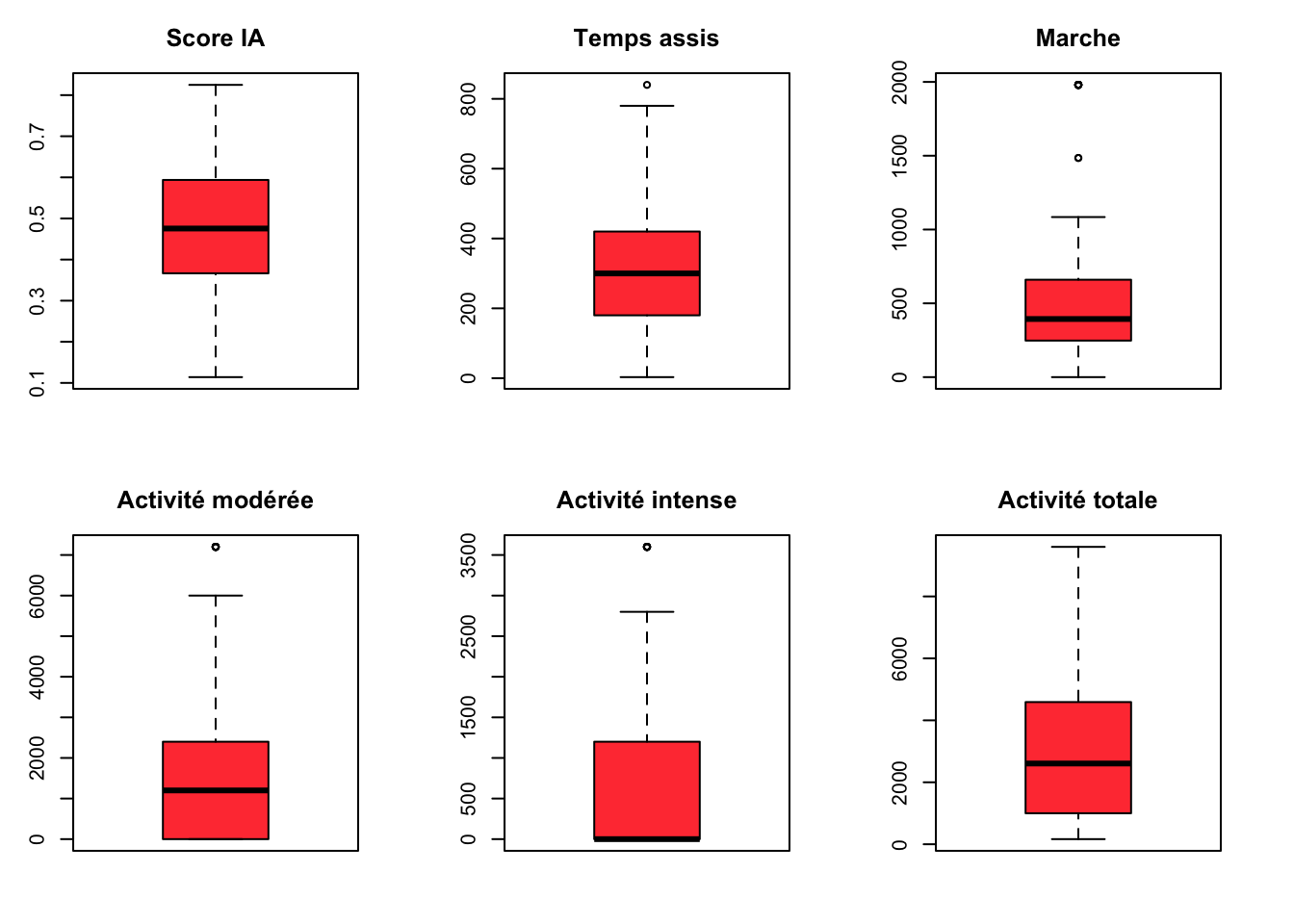
Des valeurs extrêmes sont visualisées dans l’ensemble des données liées à l’activité physique ainsi que sur les données de marche.
Technique d’imputation de données abérrantes par winzorisation
Pour éviter de supprimer les valeurs, on utilise la technique de winzorisation pour ramener les valeurs dans les limites des boîtes à moustache.
Hypothèse H0 : les données d’activitées physiques et le score suivent une distribution de loi normale
Voir le code
data_df <-data.frame(value =c(d1$Score.fertilité,d1$TempsAssis,d1$MarcheMET,d1$ModéréeMET,d1$IntensitéMET,d1$TotalMET),group =rep(c("Score de fertilité","Temps Assis","Activité de marche","Activité modérée","Activité intense","Activité total"),each =146))shapiro_results <- data_df %>%group_by(group) %>%summarise(shapiro_p =shapiro.test(value)$p.value)p <-ggplot(data_df, aes(x = value, fill = group)) +geom_histogram(bins =30, alpha =0.5) +labs(title ="Histogrammes par groupe avec p-values du test de Shapiro-Wilk", x ="Valeurs", y ="Fréquence") +facet_wrap(~ group, scales ="free") +theme_minimal() +theme(legend.position ="none") +geom_text(data = shapiro_results, aes(x =Inf, y =Inf, label =paste("p-value:", round(shapiro_p, 4))),hjust =1.1, vjust =1.1, size =2.5)
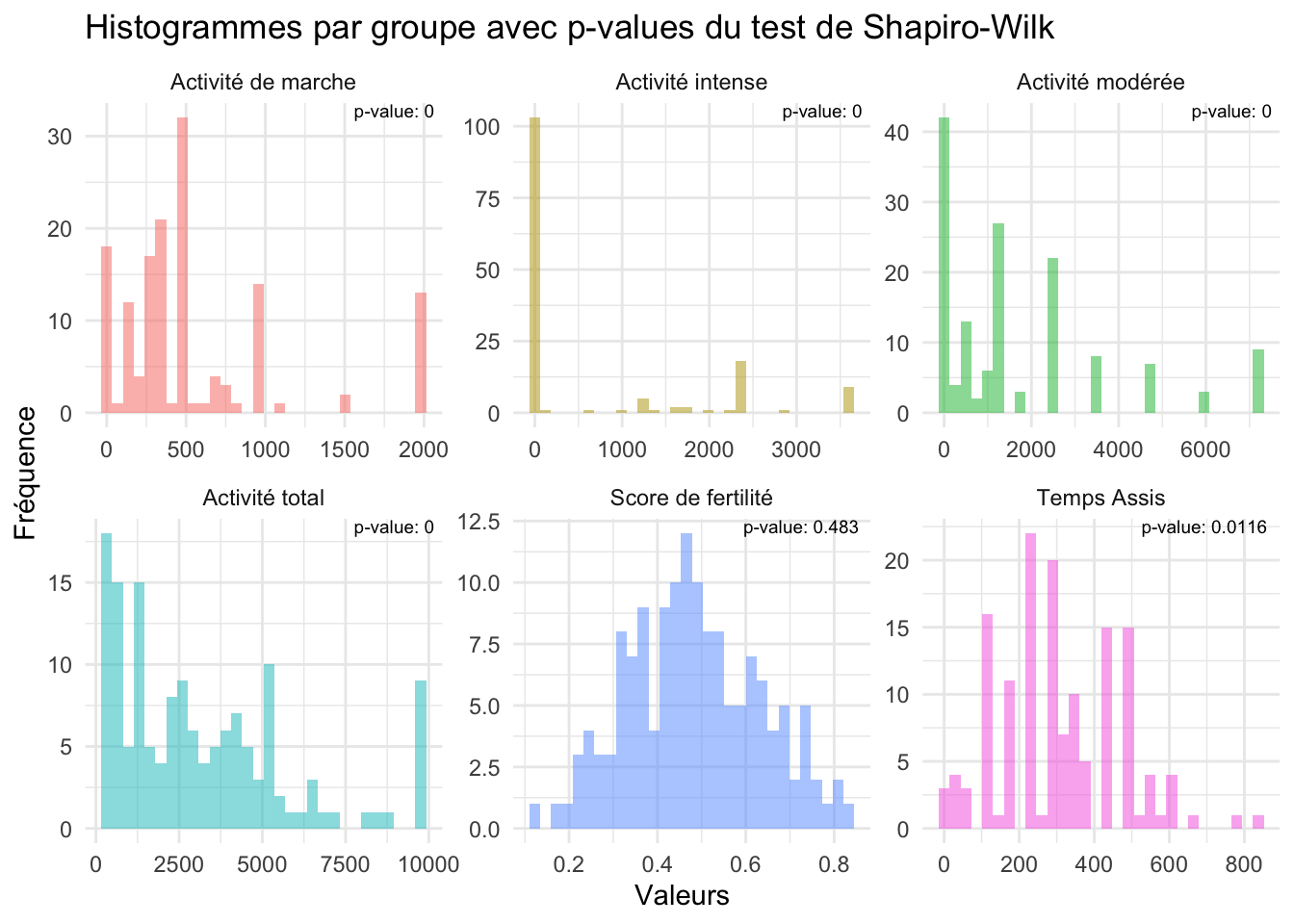
Seules la variables du score de fertilité présente une p-value supérier à 0,05 acceptant donc l’hypothèse H0 et la normalité de la distributions des valeurs du score de fertilité. Les p-values des autres variables étant trop inférieur. Cependant, comme chez l’homme, on observe que le temps assis suit une tendance dans la normalité de ses distributions (observation graphique).
4. Conclusion
L’analyse des données brutes montrent un total de 30 valeurs manquantes répartie dans les mesures du temps assis et de l’activité de marche. Le nouveau jeu de donnée (d1) créer tient compte de notre analyse et comporte les données de (d) avec l’imputation par les proches voisins et la winzorisation des données. L’observation de la normalité des distribution révèle une distribution normal significative pour le score de fertilité. Sans être significatif, le temps assis semblent suivre une tendance de normalité dans sa distribution.
Partie II : Analyse des données brutes
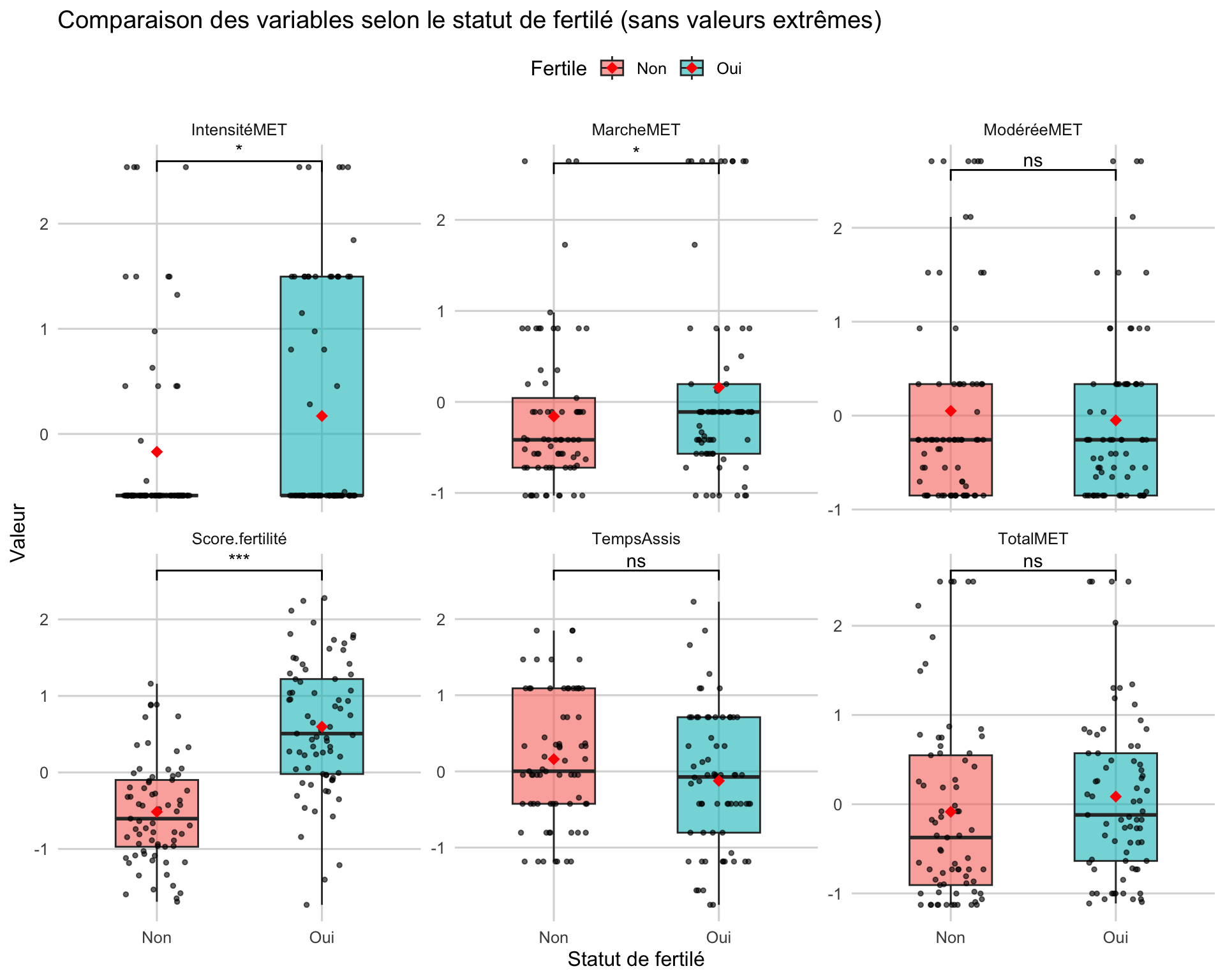
1. Comparaison des moyennes selon le status de fertilité
Hypothèse H0 : il n’y a pas de différence entre les moyennes des variables d’activité issus du groupe fertile et celle issus du groupe infertile
Ici on observe dans un premier temps que le score de fertilité est significativement différent entre les groupes fertiles et infertile (p < 0,001). Dans les données d’activitées physique, l’activité physique intense et l’activité de marche se retrouve plus élevés pour les groupes fertiles (p < 0,05). Le reste des variables n’étant pas significatif.
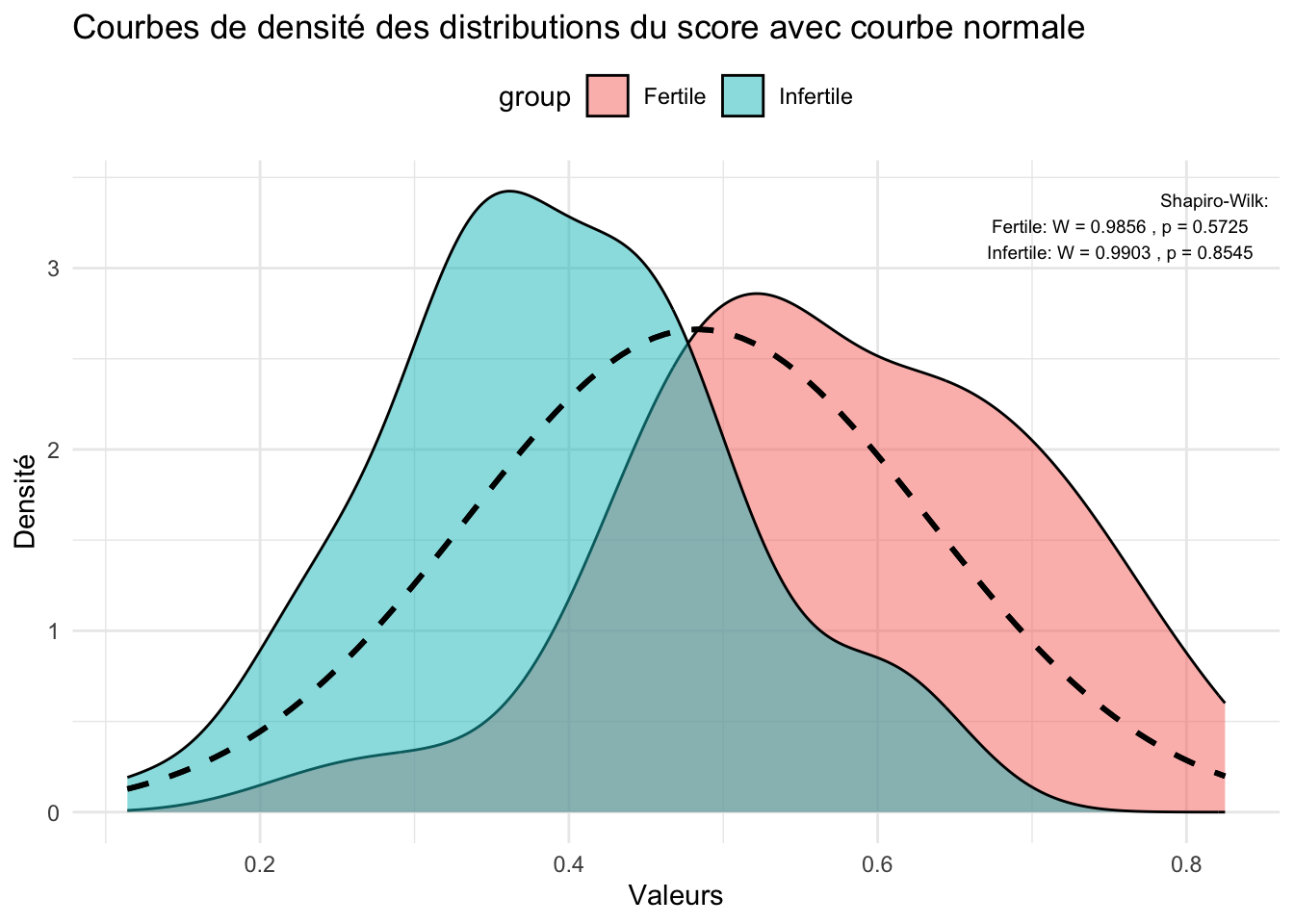
2. Vérification d’un score représentant la fertilité
Hypothèse H0 : les distributions du score dans les groupes de fertilité suivent une loi normale
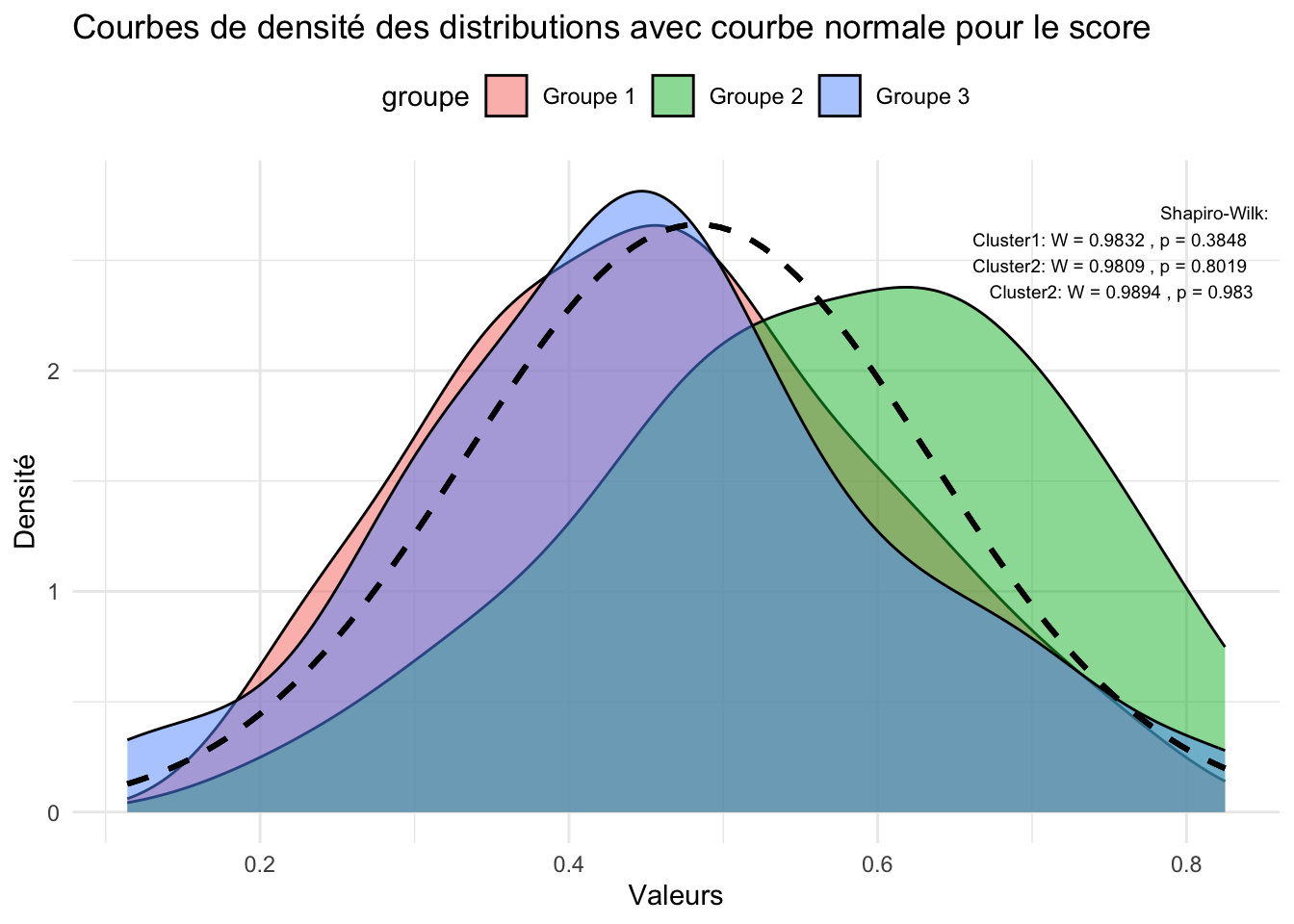
data <-data.frame(Fertile,Infertile)data_df2 <-data.frame(value =c(data$Fertile,data$Infertile),group =rep(c("Fertile","Infertile"),each =73))shapiro_Fertile <-shapiro.test(Fertile)shapiro_Infertile <-shapiro.test(Infertile)p2 <-ggplot(data_df2, aes(x = value, fill = group)) +geom_density(alpha =0.5) +stat_function(fun = dnorm, args =list(mean =mean(data_df2$value), sd =sd(data_df2$value)), color ="black", size =1, linetype ="dashed") +# Courbe normalelabs(title ="Courbes de densité des distributions du score avec courbe normale", x ="Valeurs", y ="Densité") +theme_minimal() +theme(legend.position ="top")
Warning: Using `size` aesthetic for lines was deprecated in ggplot2 3.4.0.
ℹ Please use `linewidth` instead.
p2 <- p2 +annotate("text", x =Inf, y =Inf, label =paste("Shapiro-Wilk:\nFertile: W =", round(shapiro_Fertile$statistic, 4), ", p =", round(shapiro_Fertile$p.value, 4), "\nInfertile: W =", round(shapiro_Infertile$statistic, 4), ", p =", round(shapiro_Infertile$p.value, 4)), hjust =1.1, vjust =1.5, size =2.5, color ="black", parse =FALSE)
On accepte bien l’hypothèse H0 qui montrent la normalité des distributions du score au sein du groupe fertile et infertile. On peut réaliser un test d’homogénéité de Student
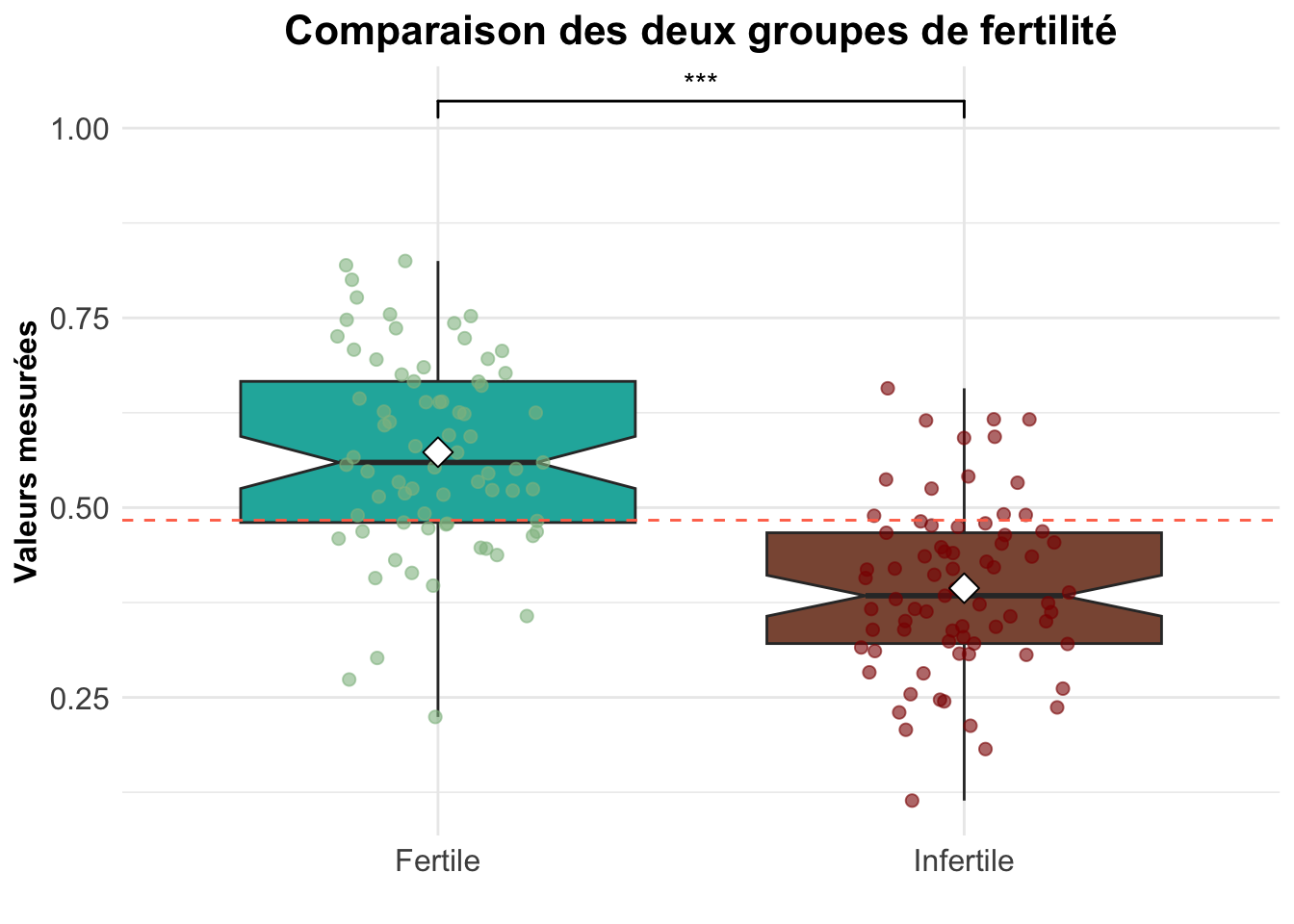
Hypothèse H0 : il n’y a pas de différence significative entre les groupes fertiles et infertiles sur le score de fertilité
Afficher/Masque le résultat
resultat_test
Welch Two Sample t-test
data: Fertile and Infertile
t = 8.9954, df = 141.24, p-value = 1.41e-15
alternative hypothesis: true difference in means is not equal to 0
95 percent confidence interval:
0.1397730 0.2185128
sample estimates:
mean of x mean of y
0.5729976 0.3938547
Avec un t = 8,9954 on peut rejeté l’hypothèse nul avec un risque alpha de 0,001. Le score de fertilité est significativement différente entre le groupe fertile et infertile. De ce fait, un score élevé est associé au groupe d’individus fertile et un score plus faible, au groupe d’infertile.
Le score de fertilité permet bien de distinguer une population fertile d’une population infertile.
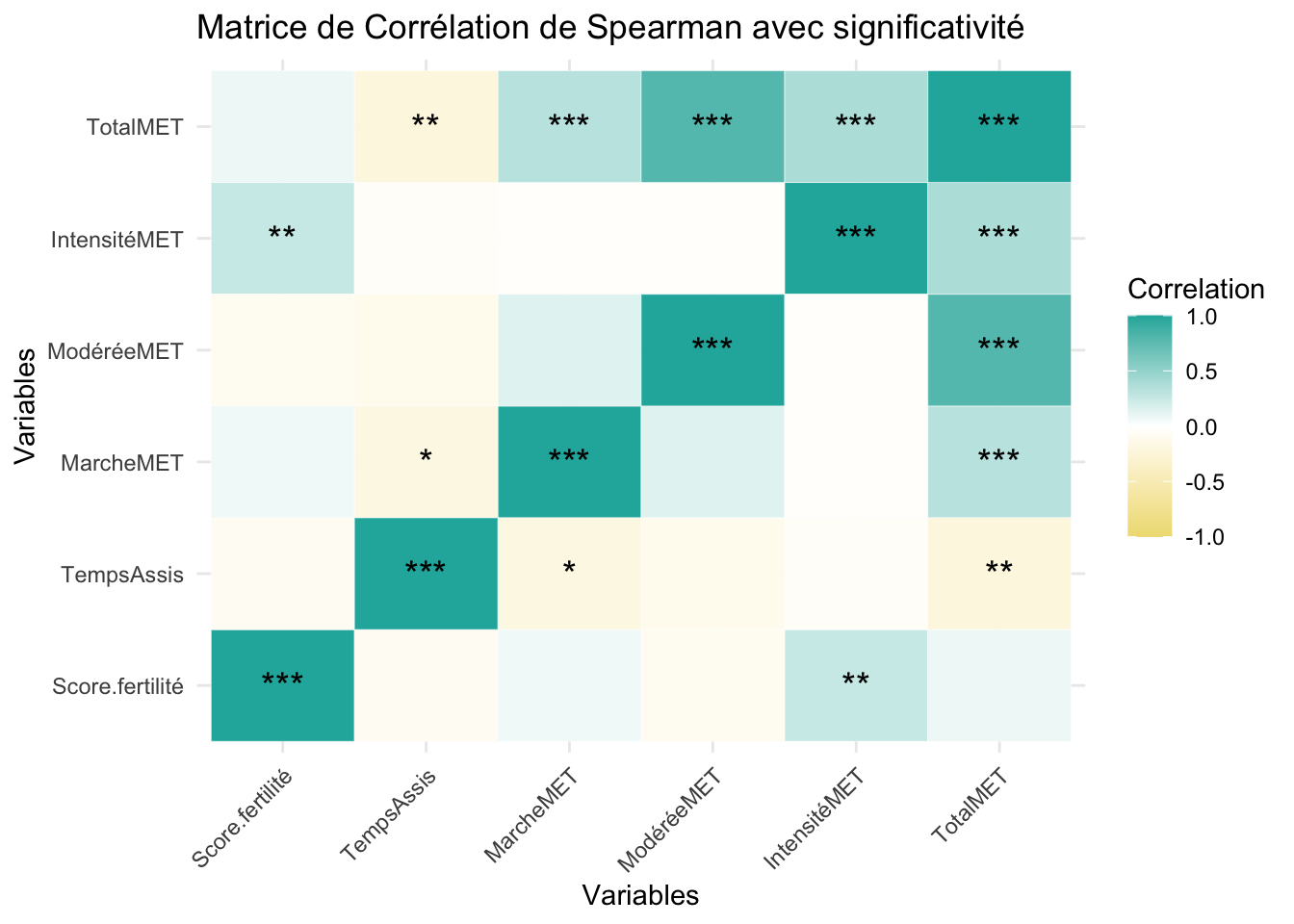
3. Corrélation des variables
Voir le code
# Matrice de corrélation non paramétrique de Spearmancor_matrix <-cor(d1, use ="pairwise.complete.obs", method ="spearman")# p-valueget_pvalue <-function(x, y) { test <-cor.test(x, y, method ="spearman")return(test$p.value)}# Matrice de p-valuesp_matrix <-sapply(d1, function(x) sapply(d1, function(y) get_pvalue(x, y)))p_adjusted <-p.adjust(as.vector(p_matrix), method ="BH")cor_long <-as.data.frame(as.table(cor_matrix))p_long <-as.data.frame(as.table(p_matrix))colnames(cor_long) <-c("Var1", "Var2", "Correlation")colnames(p_long) <-c("Var1", "Var2", "P_value")# Ajouter les p-values corrigéesp_long$P_value_corrected <- p_adjustedp_long$Significance <-cut(p_long$P_value, breaks =c(-Inf, 0.001, 0.01, 0.05, Inf), labels =c("***", "**", "*", ""), right =TRUE)p_long$Significance <-as.character(p_long$Significance) # Convertir en caractère# Fusionner les matrices de corrélation et de p-valuescor_p_long <-merge(cor_long, p_long[, c("Var1", "Var2", "P_value_corrected")], by =c("Var1", "Var2"))# Fusionner avec les p-values d'originecor_p_long <-merge(cor_long, p_long, by =c("Var1", "Var2"))
La corrélation des variables semblent montrer une cohérence nécessaire dans le cadre de mesure réaliser par autodéclaration. Le temps assis est corrélé négativement au temps d’activité de marche et à l’activité physique total. Quant a l’activité physiqsue total, elle est bien corrélé positivement au autre variable d’activité physique et négativement pour le temps passer en position assise. Le score de fertilité n’est ici corrélé qu’avec l’activité physique intense.
4. Régression linéaire sur le score de fertilité
Voir le code
# Restructurer les donnéesd1_melted <-melt(d1, id.vars ="Score.fertilité", variable.name ="Variable", value.name ="Valeur")# Fonction pour ajuster le modèle et récupérer les coefficients, p-values, et symboles de significativitéget_regression_info <-function(data) { model <-lm(Score.fertilité ~ Valeur, data = data) summary_model <-summary(model) coeff <- summary_model$coefficients[2, 1] p_value <- summary_model$coefficients[2, 4]# Déterminer le symbole de significativité significance_symbol <-ifelse(p_value <0.001, "***",ifelse(p_value <0.01, "**",ifelse(p_value <0.05, "*", "")))return(data.frame(Coeff = coeff, p_value = p_value, Significance = significance_symbol))}# Appliquer la fonction à chaque variableregression_results <- d1_melted %>%group_by(Variable) %>%do(get_regression_info(.)) %>%ungroup() # Dégrouper les résultats pour éviter des problèmes lors de l'affichage# Tracer les régressions avec coefficients et p-valuesp3 <-ggplot(d1_melted, aes(x = Valeur, y = Score.fertilité, color = Variable)) +geom_point() +# Ajoute les pointsgeom_smooth(method ="lm", se =FALSE) +# Ajoute les lignes de régressionlabs(title ="Régressions des Variables sur le Score de Fertilité", x ="Valeur des Variables Explicatives", y ="Score de Fertilité") +theme_minimal()# Ajouter les coefficients et p-values sur le graphique avec symboles de significativité# Créer une position pour chaque textetext_positions <-data.frame(Variable = regression_results$Variable,x =max(d1_melted$Valeur, na.rm =TRUE) *0.85, # Position x fixey =seq(max(d1$Score.fertilité, na.rm =TRUE) *0.90, max(d1$Score.fertilité, na.rm =TRUE) *0.65, length.out =nrow(regression_results)) # Position y avec espacement)# Joindre les résultats de régression aux positionstext_data <-merge(regression_results, text_positions, by ="Variable")# Tracer le graphique avec les textes et les symbolesp3 <- p3 +geom_text(data = text_data, aes(x = x, y = y, label =sprintf("Coeff: %.2f\np-value: %.3f\n%s", Coeff, p_value, Significance)), hjust =1, vjust =1, # Ajustement de la positionsize =4, check_overlap =TRUE)# Convertir en graphique interactifinteractive_plot <-ggplotly(p3)
`geom_smooth()` using formula = 'y ~ x'
La corrélation linéaire nous informes que de quelque élement de plus. On confirme bien une corrélation positive entre le score et l’activitié phyique total. Et il semble y avoir également un lien entre le temps assis qui régulerais à la baisse le score de fertilité.
Visualisation en 3 dimensions
Les variables d’activités physique intense (p-value < 0,05) et d’activité physique total (p-value 0,3) semblent être les varirables les plus impactant sur le score de fertilité
5. Conclusion
L’analyse de nos données brutes chez la femme et plus convaincante que chez l’homme. En effet, la variable d’activité liés à la marche ce montre significatif entre les groupes fertiles et infertiles. Le score de fertilité est encore une fois bien représentatif, en test paramétrique, de la différence entre les individus fertiles et infertiles. Il semblerait cependant que celui-ci soit moins corrélé aux différentes activités physique là ou seule l’activité physique intense est corrélé au score. Toutes fois, l’activitié physique total est bien corrélé au reste de nos activité physique.
Partie III : Réalisation de l’Analyse factorielle
Cette étape va se consacrer à la projection et à la compression des données par ACP pour n’en garder que celles qui portent suffisament d’informations pour expliquer au mieux notre problématique. La normalisation des données est automatiquement réalisé par la fonction PCA de FactoMineR.
On utilise le test de KMO pour vérifier la fiabilité de nos interprétations. Les résultats sont regroupés dans le tableau suivant :
Variable
Test de KMO
Score de fertilité
0,8
Temps Assis
0,68
Marche
0,11
Activité modérée
0,26
Activité intense
0,10
Activité total
0,31
Le score de KMO se trouve moins restreingant que les données issus de la population masculine. L’analyse en PCA revelera donc quelque élement concernant le regroupement des données.
1. Réalisation de la PCA
res.pca<-PCA(d1,graph =FALSE,ncp =6)
Voir le code
p3 <-fviz_pca_var (res.pca, col.var ="cos2",gradient.cols =c("#00AFBB", "#E7B800", "#FC4E07"),repel =TRUE# Évite le chevauchement de texte ) p4 <-fviz_pca_ind (res.pca, col.ind ="cos2",gradient.cols =c("#00AFBB", "#E7B800", "#FC4E07"),repel =TRUE# Évite le chevauchement de texte )# Rendre le graphique interactif avec `ggplotly`p_interactive <-ggplotly(p4)
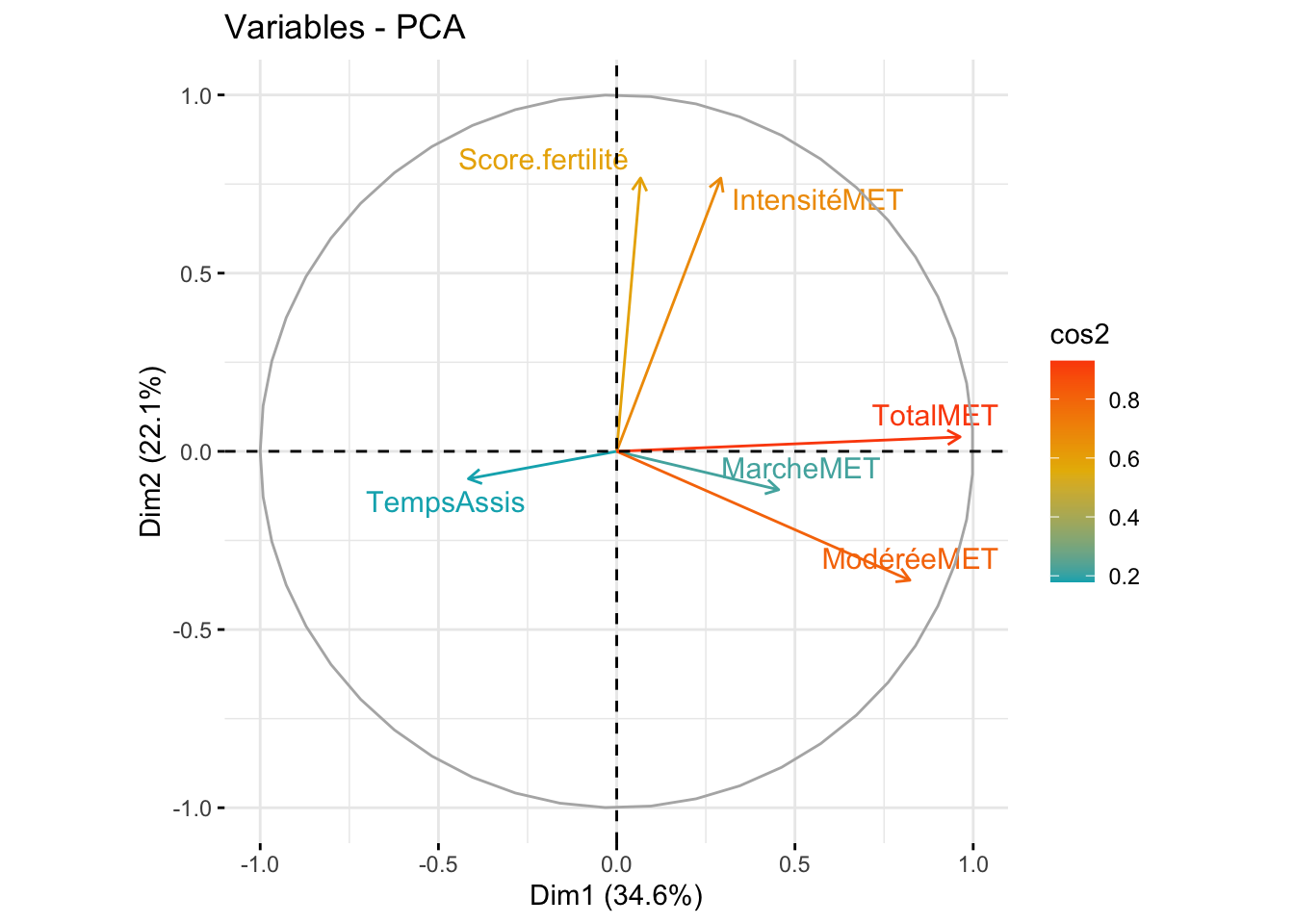
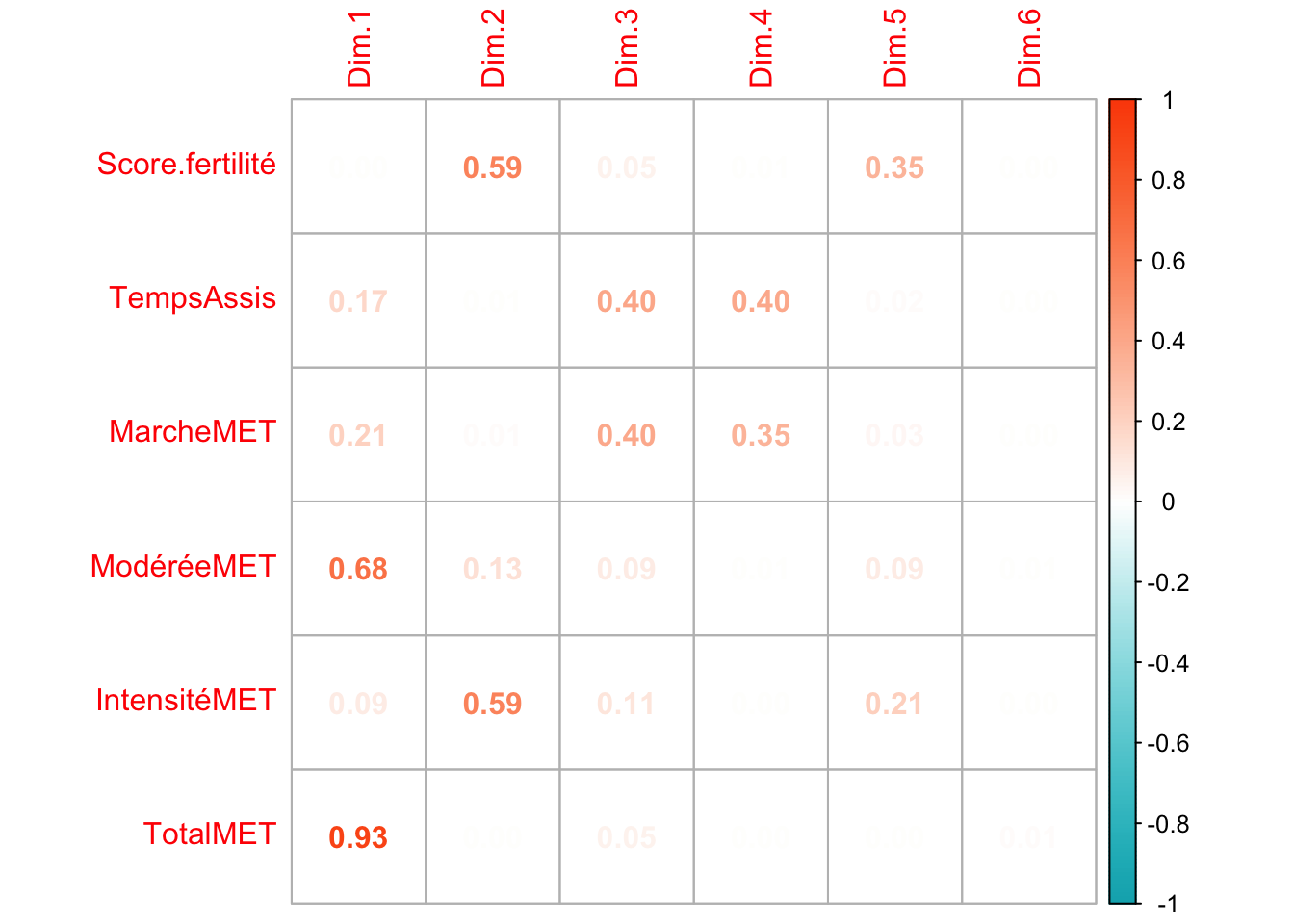
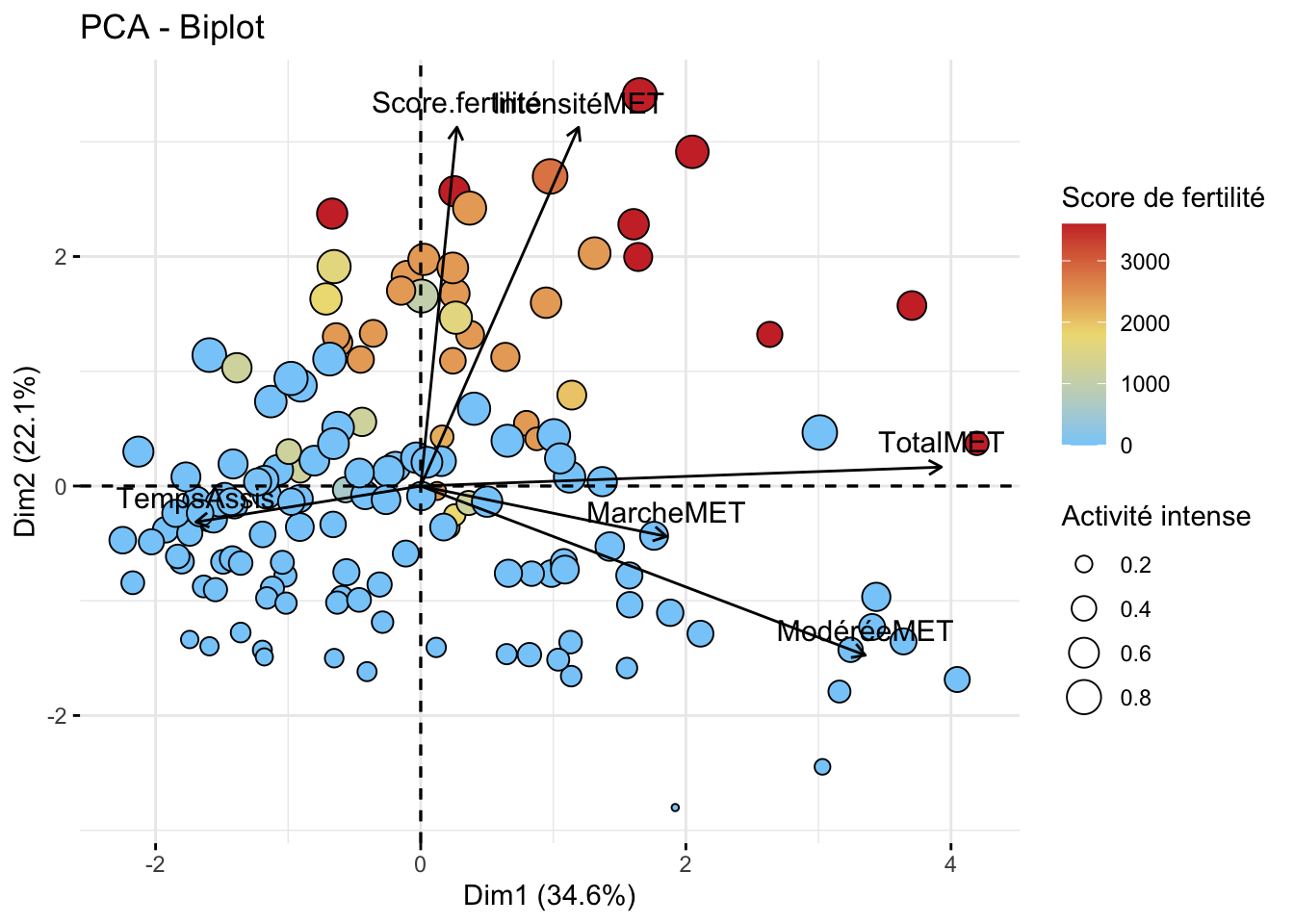
L’axe 1 semblent représenté la majorité de nos observation. Concernant le poids de variable, on voit que le score de fertilité semblent prendre plus d’importance (contrairement à ce qu’on peut observer chez l’homme). Les variables les plus influentes sont l’activité modérée, l’activité total et l’activité intense.
Visualisation de la distribution de l’inertie des axes
res <-get_pca_var(res.pca)
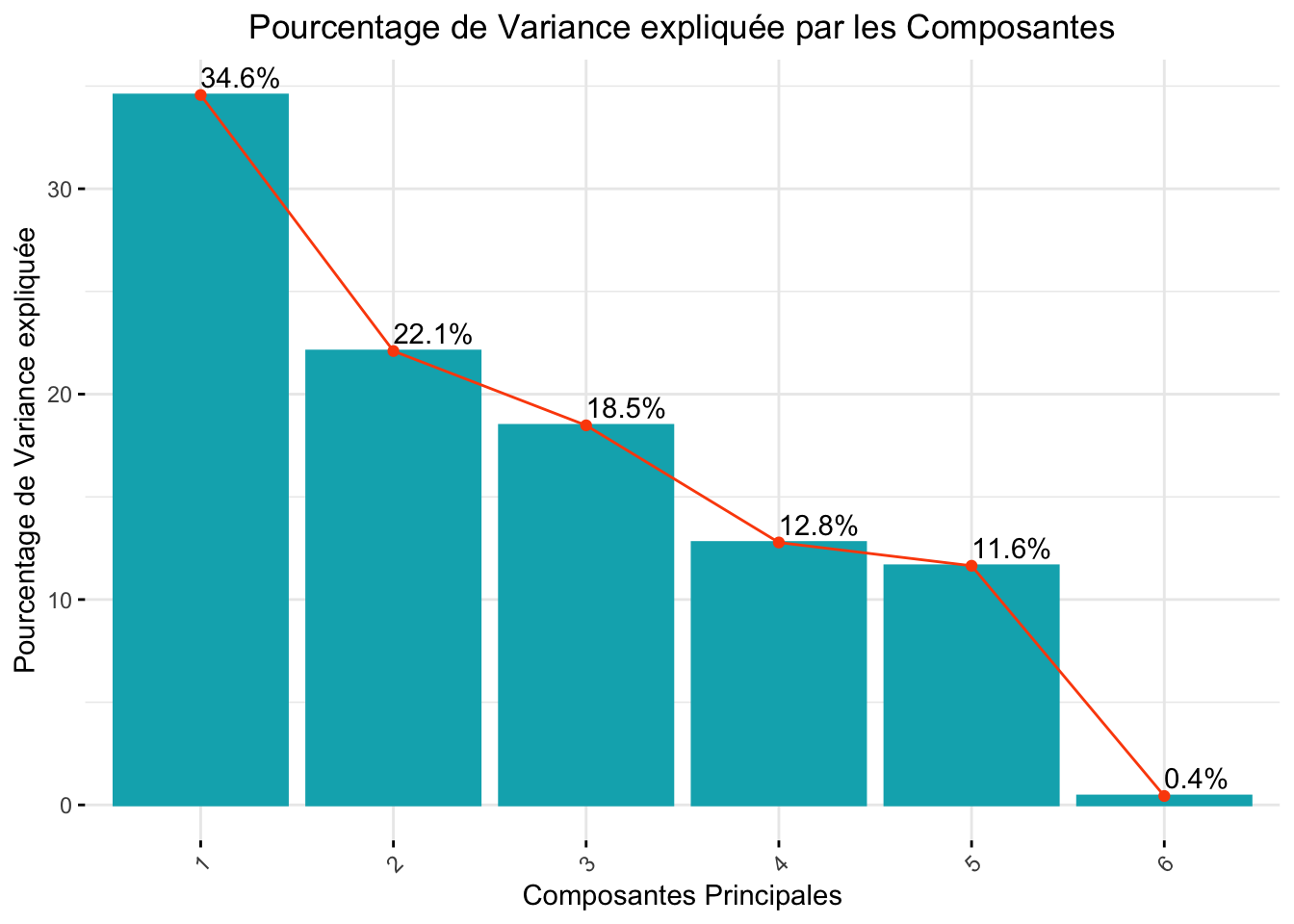
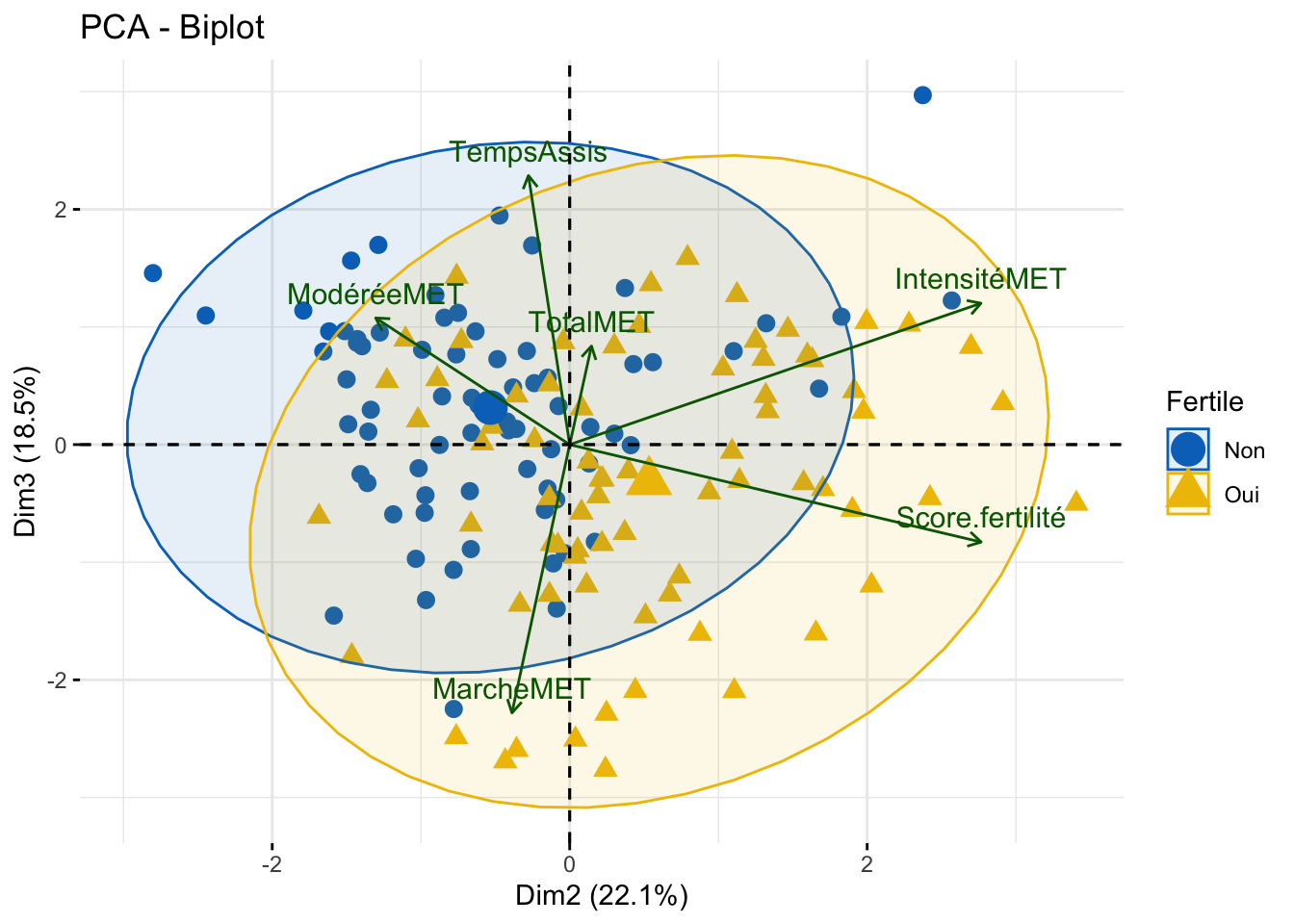
Les 2 premiers axes représentent plsu de 50% (56,7) des observations. A noter que l’axe 3 n’est pas si écarté que ça, en terme de représentation, que l’axe 2. Ce premiers axes est majoritairement influencé par l’activité total, l’axe 2 est quant a lui influencer par le score de fertilité et l’activité physique intense.
Analyse de la répartition des variables
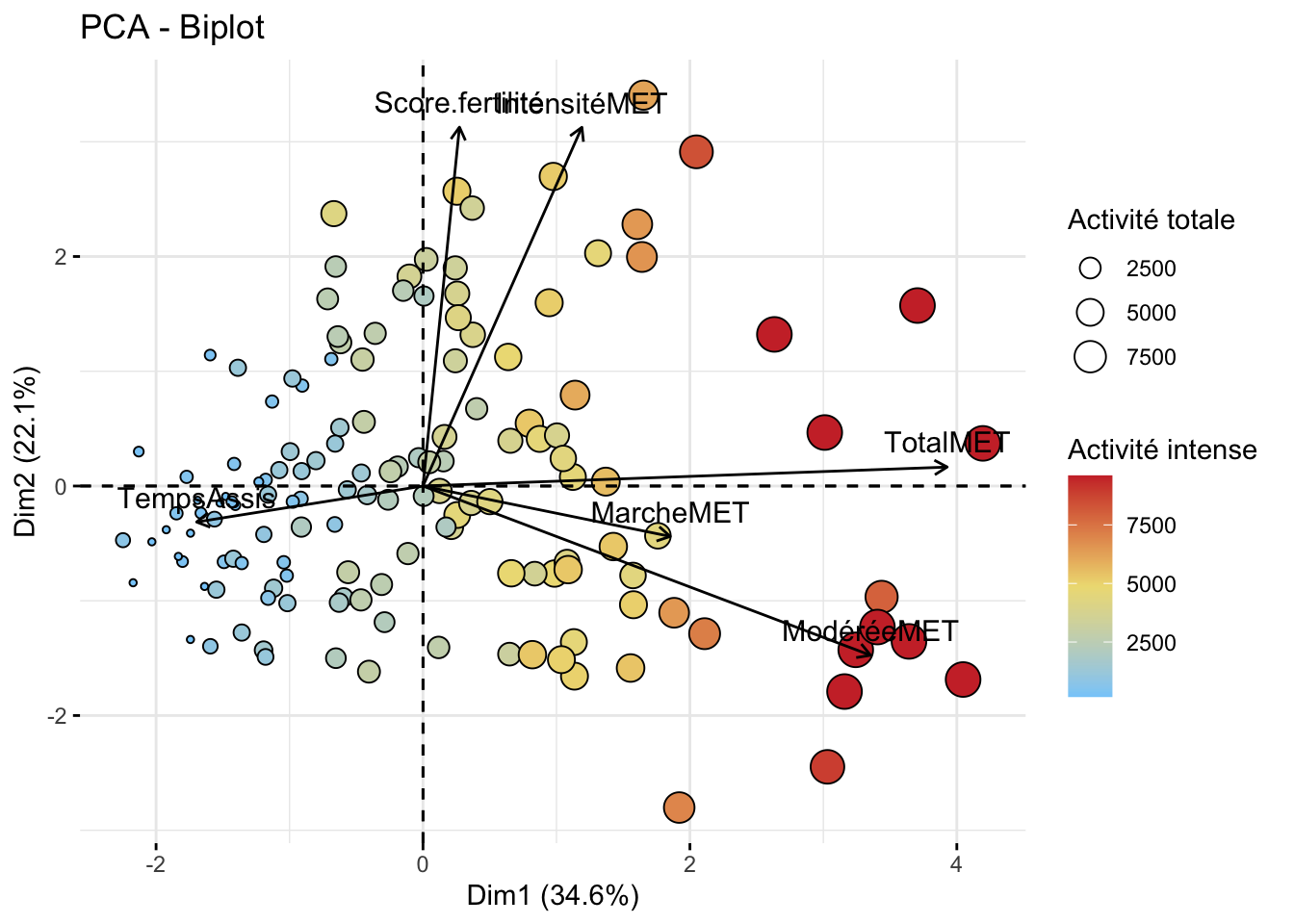
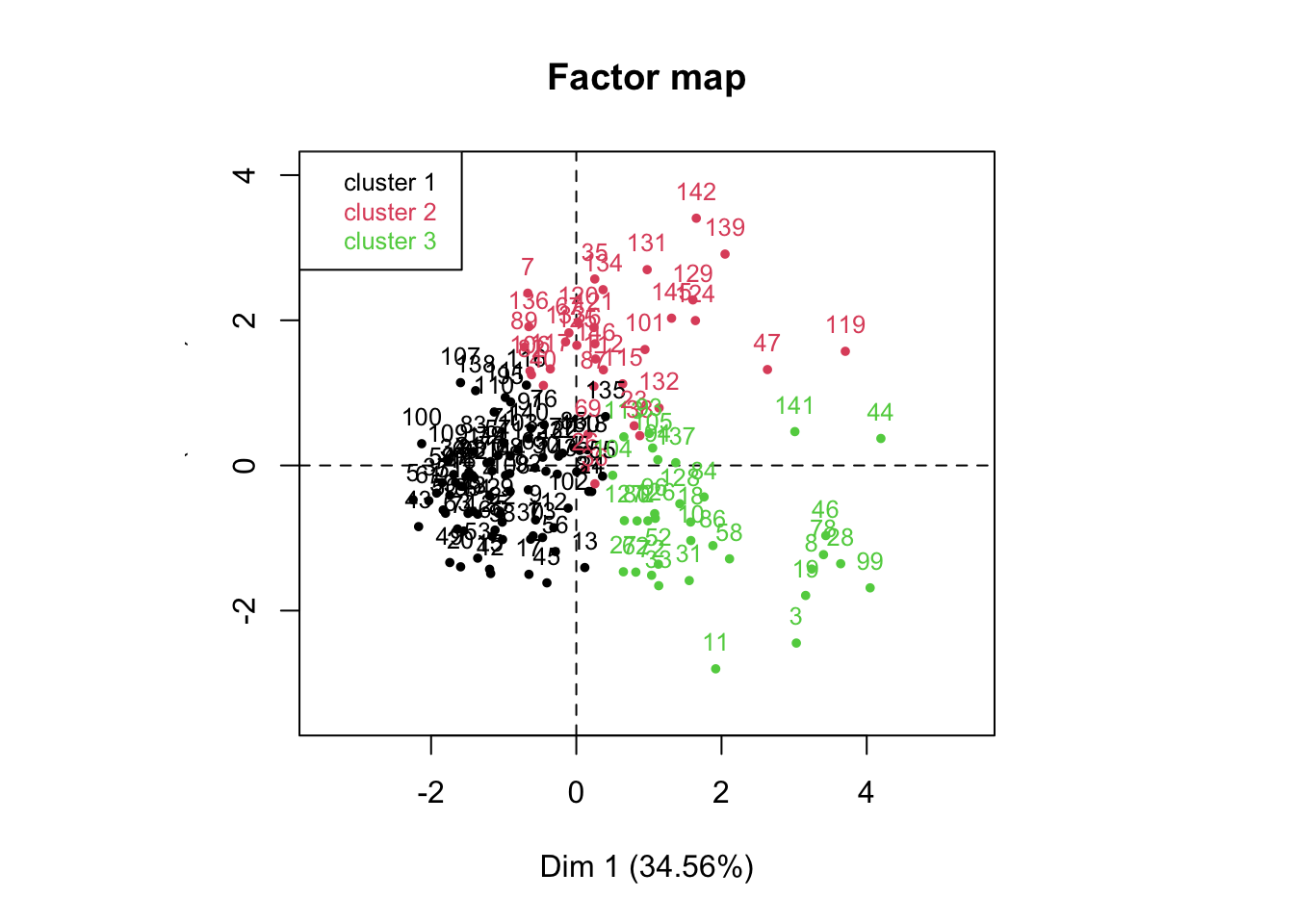
Dans une première analyse, on observe que les individus ayant une activité physique sont regroupé à droite sur la dimension 1. L’activité de marche et le temps assis n’a pas montré de regroupement d’individus en particulier sur l’axe 1 et 2. Quant au score, il est principalement visualisé en haut à droite du graphique. Au final, il est assez difficile de voir des clusters d’individus, même si on a des variables qui s’apprêtent à une utilisation de la PCA
Visualisation interractif de la PCA
Si le bouton ne marche pas, utiliser le lien externe : faire la visualisation sur R
Résultat de la PCA sur la fertilité
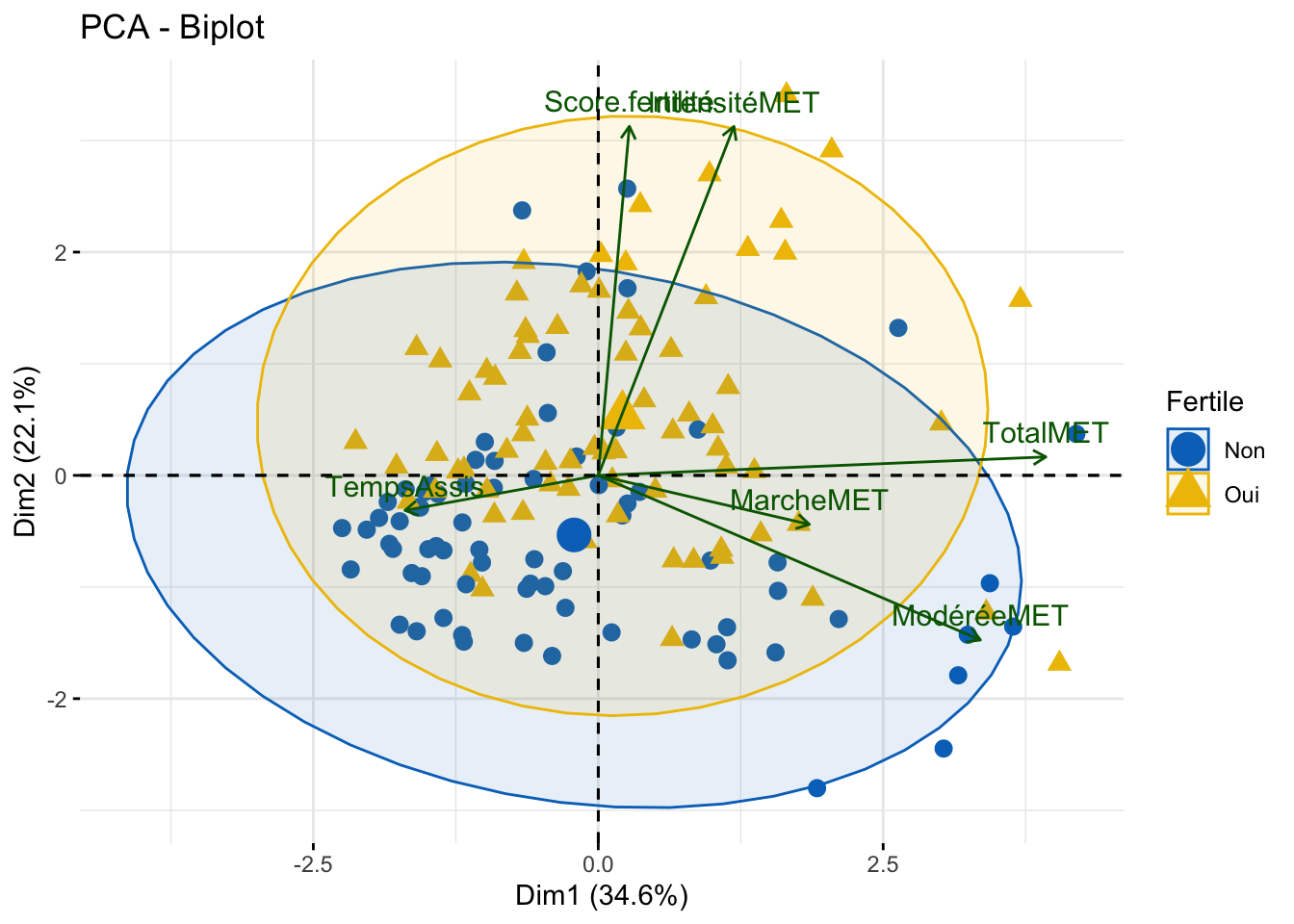
Pour terminer l’analyse en PCA, on projette la fertilité sur les observations de la PCA. De manière distingtiuf, on remarque tout de même un regroupement des individus fertiles sur l’axe supérieur (dimension 1).
On remarque que les 2 groupes de fertilité sont bien distingué, mais on peut noter qu’il existe une hétérogénéité des individus au sein des groupes.
Validation croisée du modèle
Voir le code
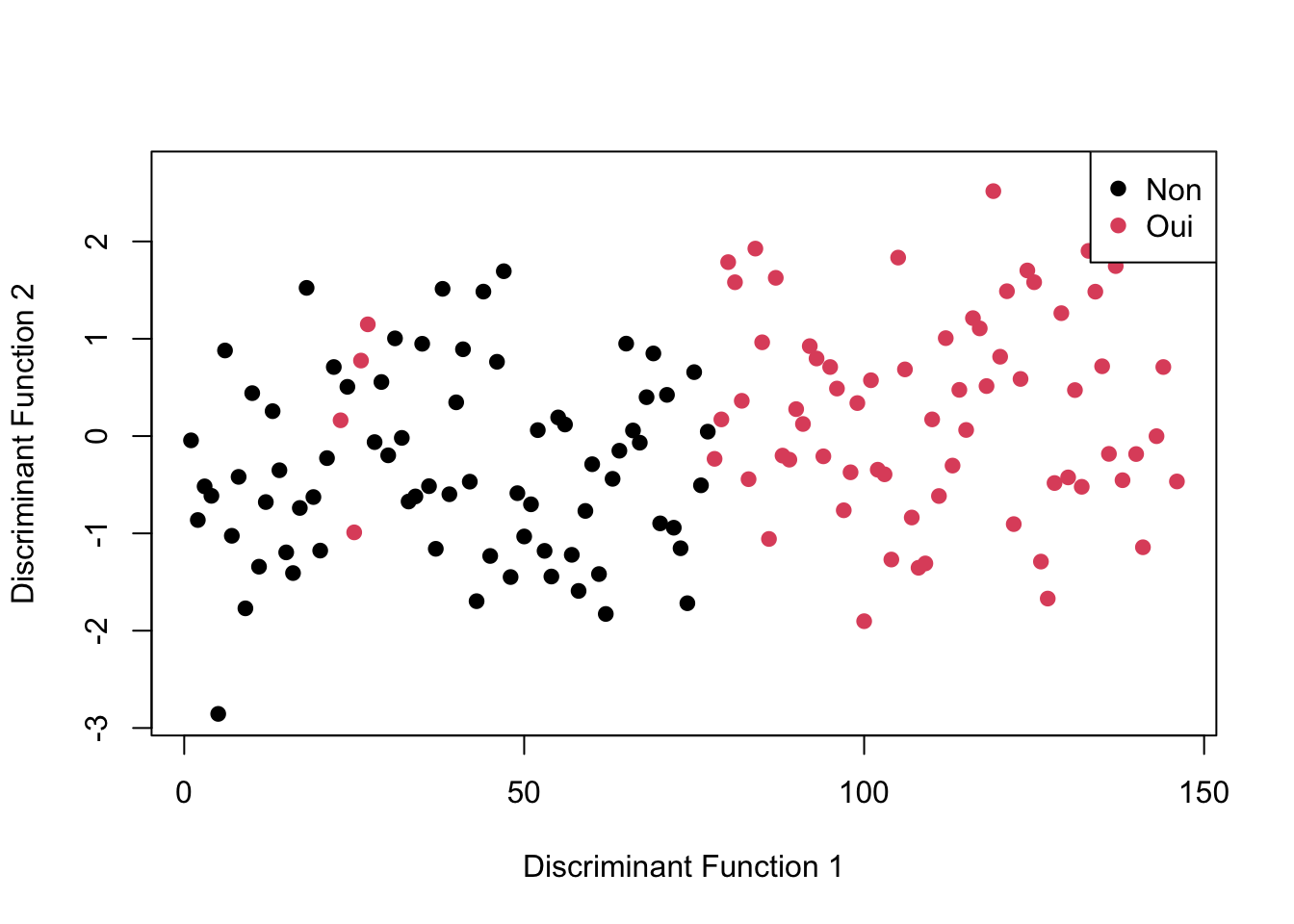
set.seed(69)# Définir le nombre de foldsk <-10# Définir la méthode de validation croiséecontrol <-trainControl(method ="cv", number = k)# Ajuster le modèle LDA avec validation croiséelda_model <-train(Fertile ~ TempsAssis + MarcheMET + ModéréeMET + IntensitéMET + TotalMET, data = d9, method ="lda", trControl = control)
La précision du modèle ne classifie pas bien les observations, alié avec un Kappa inférieur à 0,2. Ça suggère que les prédictions du modèle ne sont pas beaucoup meilleurs que celles d’un modèle aléatoire. C’est surement dû à nos classes déséquilibrés.
3. Amélioration par bootstrap
Visualisation des résultats par test statistique
Voir le code
# On créer une nouvelle data avec les variables continu mais sans le scored13=d1[,c(2,3,4,5,6)]# Fonction de bootstrap pour estimer la moyenne d'une variablebootstrap_mean <-function(data, column_name, B =1000) { n <-nrow(data) means <-numeric(B)for (i in1:B) { sample_indices <-sample(1:n, size = n, replace =TRUE) means[i] <-mean(data[[column_name]][sample_indices]) }return(means)}# Appliquer le bootstrap à chaque variableB <-1000bootstrap_results <-list()for (var innames(d13)) { bootstrap_results[[var]] <-bootstrap_mean(d13, var, B)}# Calculer les intervalles de confiance pour chaque variableci_results <-list()for (var innames(d1)) { ci_lower <-quantile(bootstrap_results[[var]], 0.025) ci_upper <-quantile(bootstrap_results[[var]], 0.975) ci_results[[var]] <-c(lower = ci_lower, upper = ci_upper)}real_means <-sapply(d13, mean)shapiro_results <-sapply(bootstrap_results, function(x) shapiro.test(x)$p.value)shapiro_df <-data.frame(Variable =names(shapiro_results), p_value = shapiro_results)
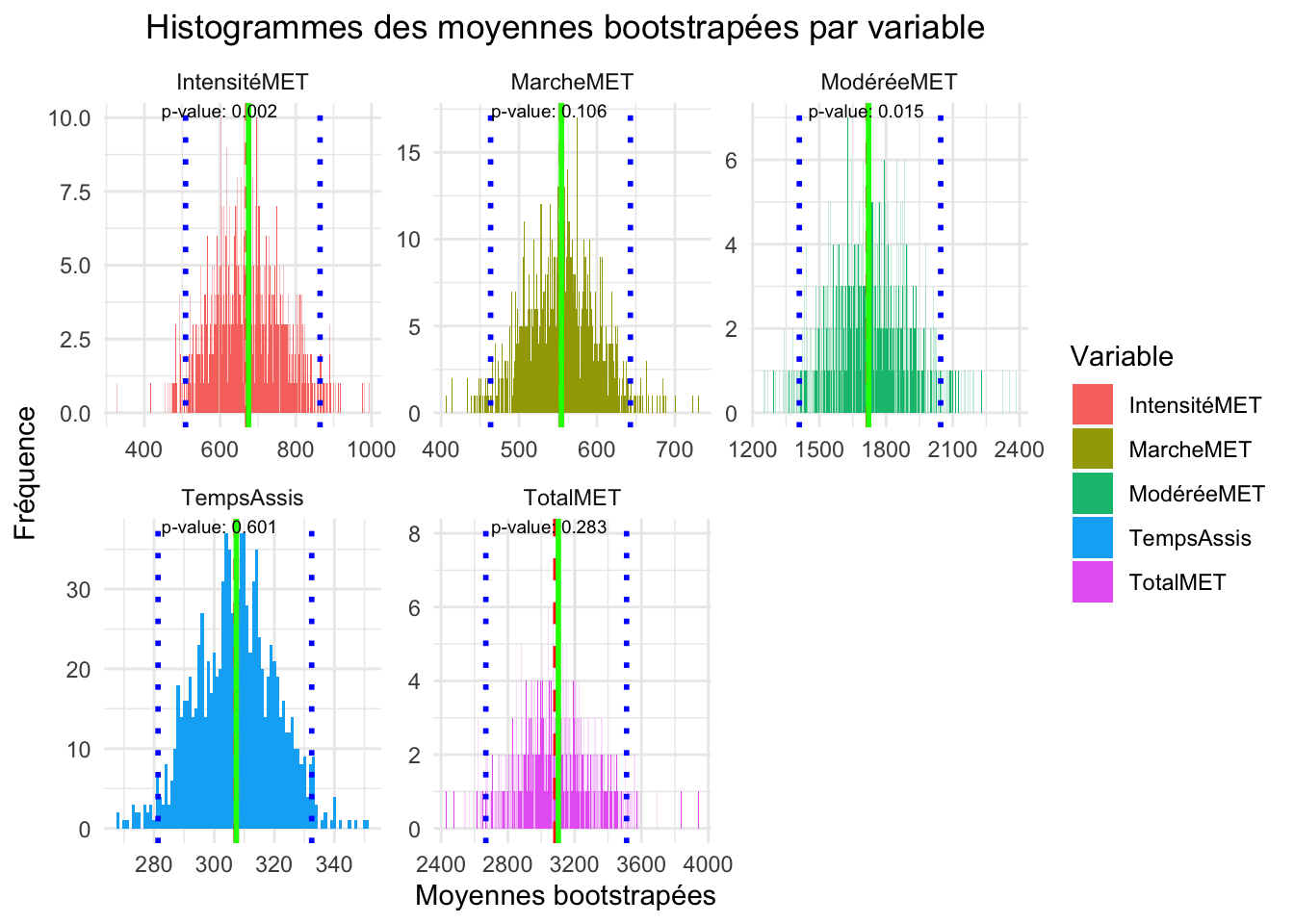
Pour rappel, l’axe des abscisses est la valeurs des moyennes bootstrapées. Les intervalles (bins) ou chacun regroupe un nombre n de valeur. L’axe des ordonnées montre le nombre de fois que les valeurs de la variable tombent dans le bins (on parle de denstié de valeur. La symétrie montre la normalité des distributions avec des p-value confirmant le test de Shapiro. Les moyennes représentent en générale une tendance (fréquence élevé). L’équivalence entre la moyenne bootstrapé et la moyenne réelle montre une bonne représentation de la population.
Test de différence de moyenne
Voir le code
# Fonction pour calculer la différence de moyenne entre les groupes 'Oui' et 'Non' pour une variable donnéebootstrap_diff_mean <-function(data, group_var, value_var, B =1000) {# Séparer les groupes group_oui <- data[data[[group_var]] =="Oui", value_var] group_non <- data[data[[group_var]] =="Non", value_var] n_oui <-length(group_oui) n_non <-length(group_non) diff_means <-numeric(B) # Stocker les différences de moyennes# Boucle pour le bootstrapfor (i in1:B) {# Bootstrap pour le groupe "Oui" sample_oui <-sample(group_oui, size = n_oui, replace =TRUE)# Bootstrap pour le groupe "Non" sample_non <-sample(group_non, size = n_non, replace =TRUE)# Calculer la différence de moyenne entre "Oui" et "Non" diff_means[i] <-mean(sample_oui) -mean(sample_non) }return(diff_means)}# Appliquer le bootstrap pour chaque variable d'intérêtvariables_continues <-c("Score.fertilité", "TempsAssis", "MarcheMET", "ModéréeMET", "IntensitéMET", "TotalMET")bootstrap_diff_results <-list()for (var in variables_continues) { bootstrap_diff_results[[var]] <-bootstrap_diff_mean(d9, "Fertile", var, B =1000)}# Calcul des intervalles de confiance pour chaque variableci_diff_results <-list()for (var in variables_continues) { ci_lower <-quantile(bootstrap_diff_results[[var]], 0.025) # Limite inférieure (2.5%) ci_upper <-quantile(bootstrap_diff_results[[var]], 0.975) # Limite supérieure (97.5%) ci_diff_results[[var]] <-c(lower = ci_lower, upper = ci_upper)}# Afficher les intervalles de confiance des différences de moyennesci_diff_df <-do.call(rbind, ci_diff_results)colnames(ci_diff_df) <-c("CI Lower", "CI Upper") # Renommer les colonnes pour plus de clartéprint(ci_diff_df)
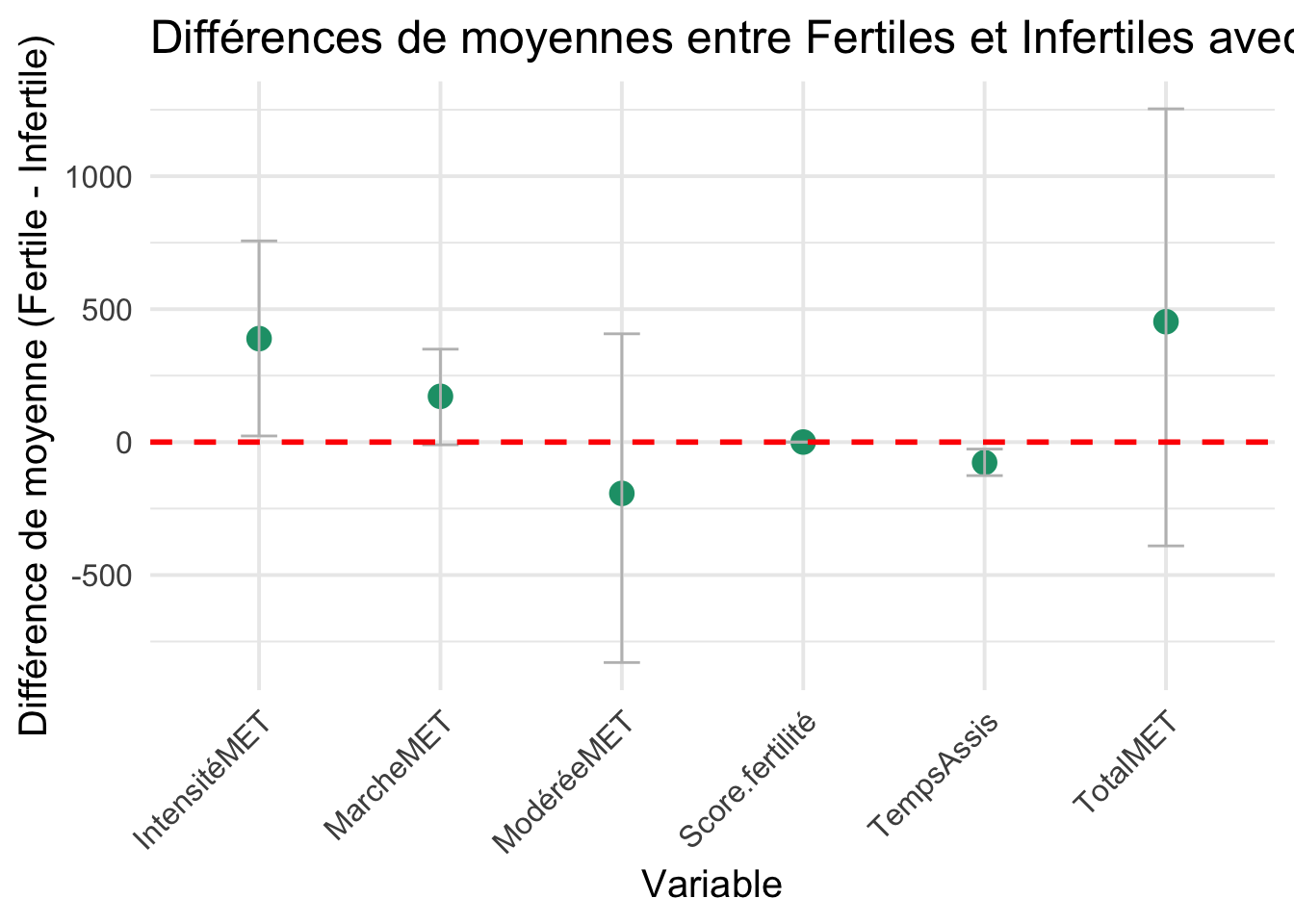
# Chargement de ggplot2library(ggplot2)# Préparer le dataframe pour ggplotdata_ci <-data.frame(Variable =rownames(ci_diff_df), # Les noms des variablesCI_Lower = ci_diff_df[, "CI Lower"], # Limite inférieureCI_Upper = ci_diff_df[, "CI Upper"], # Limite supérieureMeanDiff =c(0.178107, -77.149443, 172.041137, -193.029315, 389.135890, 452.746384) # Moyennes préalablement calculées)
Ici, on observe une significativité dans les moyennes de temps assis, de score de fertilité et d’activité physique intense. Par rapport au valeur brute, on montre ici que le temps assis pourrait également jouer un rôle dans la fertilité. La marche se montre au seuil de la significativité. Un test de permutation à également été réalisé et à montrer la même significativité pour chacune des variables.
Régression linéaire et logistique
Régression logistique
Voir le code
d15=d1d15 <-cbind(d15,APF$Fertile)colnames(d15)[ncol(d15)] <-"Fertile"d15$Fertile=as.factor(d15$Fertile)# Fonction de bootstrapbootstrap_lm <-function(data, indices) { d15 <- data[indices, ] model <-glm(Fertile ~IntensitéMET + ModéréeMET + MarcheMET + TempsAssis + Score.fertilité + TotalMET, data = d15,family = binomial)return(coef(model))}library(boot)# Application du bootstrap avec 1000 répétitionsbootstrap_results <-boot(data = d15, statistic = bootstrap_lm, R =1000)# Extraire les coefficients pour chaque échantillon bootstrapintercepts <- bootstrap_results$t[, 1]coefficients_x1 <- bootstrap_results$t[, 2] coefficients_x2 <- bootstrap_results$t[, 3] coefficients_x3 <- bootstrap_results$t[, 4] coefficients_x4 <- bootstrap_results$t[, 5]coefficients_x5 <- bootstrap_results$t[, 6]coefficients_x6 <- bootstrap_results$t[, 7] coefficients_long <-data.frame(Coefficient =c(rep("Intercept", length(intercepts)), rep("IntensitéMET", length(coefficients_x1)), rep("ModéréeMET", length(coefficients_x2)), rep("MarcheMET", length(coefficients_x3)), rep("TempsAssis", length(coefficients_x4)),rep("Score.fertilité",length(coefficients_x5)),rep("TotalMET",length(coefficients_x6))),Value =c(intercepts, coefficients_x1, coefficients_x2, coefficients_x3, coefficients_x4,coefficients_x5,coefficients_x6))# Calculer la moyenne +SD pour chaque coefficientmean_values <-aggregate(Value ~ Coefficient, data = coefficients_long, FUN = mean)sd_values <-aggregate(Value ~ Coefficient, data = coefficients_long, FUN = sd)# Calculer les p-valuesB <-1000p_values <-sapply(1:nrow(mean_values), function(i) {# t-statistic t_stat <- mean_values$Value[i] / (sd_values$Value[i] /sqrt(B)) # Diviser par sqrt(B)# Degrés de liberté pour bootstrap (B - 1) df <- B -1# p-value bilatérale2* (1-pt(abs(t_stat), df = df)) # Utiliser df ajusté})# Ajouter les p-values aux moyennes dans une nouvelle data frameresults_df <-data.frame(Coefficient = mean_values$Coefficient,Mean = mean_values$Value,p_value = p_values)results_df$Odds_Ratio <-exp(results_df$Mean)
Attaching package: 'DT'
The following objects are masked from 'package:shiny':
dataTableOutput, renderDataTable
Résultats des Coefficients de Régression linéaire
Coefficient
Mean
p_value
Odds_Ratio
IntensitéMET
0.0001732
0.0000000
1.000173e+00
Intercept
-5.6202711
0.0000000
3.623700e-03
MarcheMET
0.0005804
0.0000000
1.000581e+00
ModéréeMET
0.0000428
0.0313549
1.000043e+00
Score.fertilité
13.8049011
0.0000000
9.894466e+05
TempsAssis
-0.0042497
0.0000000
9.957593e-01
TotalMET
-0.0000570
0.0019529
9.999430e-01
Régression linéaire
Voir le code
# Fonction de bootstrapbootstrap_lm2 <-function(data, indices) { d9 <- data[indices, ] model2 <-lm(Score.fertilité ~IntensitéMET + ModéréeMET + MarcheMET + TempsAssis + TotalMET, data = d9)return(coef(model2))}# Application du bootstrap avec 1000 répétitionsbootstrap_results2 <-boot(data = d9, statistic = bootstrap_lm2, R =1000)# Extraire les coefficients pour chaque échantillon bootstrapintercepts2 <- bootstrap_results2$t[, 1]coefficients_x11 <- bootstrap_results2$t[, 2] coefficients_x22 <- bootstrap_results2$t[, 3] coefficients_x33 <- bootstrap_results2$t[, 4] coefficients_x44 <- bootstrap_results2$t[, 5]coefficients_x55 <- bootstrap_results2$t[, 6]coefficients_long2 <-data.frame(Coefficient =c(rep("Intercept", length(intercepts2)), rep("IntensitéMET", length(coefficients_x11)), rep("ModéréeMET", length(coefficients_x22)), rep("MarcheMET", length(coefficients_x33)), rep("TempsAssis", length(coefficients_x44)),rep("TotalMET",length(coefficients_x55))),Value =c(intercepts2, coefficients_x11, coefficients_x22, coefficients_x33, coefficients_x44,coefficients_x55))# Calculer la moyenne +SD pour chaque coefficientmean_values2 <-aggregate(Value ~ Coefficient, data = coefficients_long2, FUN = mean)sd_values2 <-aggregate(Value ~ Coefficient, data = coefficients_long2, FUN = sd)# Calculer les p-valuesB <-1000p_values2 <-sapply(1:nrow(mean_values2), function(i) {# t-statistic t_stat2 <- mean_values2$Value[i] / (sd_values2$Value[i] /sqrt(B)) # Diviser par sqrt(B)# Degrés de liberté pour bootstrap (B - 1) df2 <- B -1# p-value bilatérale2* (1-pt(abs(t_stat2), df = df2)) # Utiliser df ajusté})# Ajouter les p-values aux moyennes dans une nouvelle data frameresults_df2 <-data.frame(Coefficient = mean_values2$Coefficient,Mean = mean_values2$Value,p_value = p_values2)results_df2$Odds_Ratio <-exp(results_df2$Mean)
Résultats des Coefficients de Régression logistique
Coefficient
Mean
p_value
Odds_Ratio
IntensitéMET
0.0000212
0.0000000
1.0000212
Intercept
0.4946889
0.0000000
1.6399880
MarcheMET
0.0000009
0.4907032
1.0000009
ModéréeMET
-0.0000218
0.0000000
0.9999782
TempsAssis
-0.0000833
0.0000000
0.9999167
TotalMET
0.0000120
0.0000000
1.0000120
Lorsqu’on observe les données issus de la régression logistique, on observe qu’une augmentation de la marche est significativement associé à une augmentation des chances de fertilité. Quant au temps, il est lui à l’inverse classé comme une variable négatif pour les chances de fertilité.
Sur les données de régression linéaire, l’activité physique intense et total est associé significativement à une augmentation du score de fertilité. Au contraire, le temps assis et l’activité modérée est associé à une diminution de ce même score.
4. Conclusion
Avec un score KMO moyen de 0.38, les variables sont difficilement interprétable dans le cadre d’une ACP, par conséquent les résultats, aussi interprétable qu’ils soient ne permettront de conclure efficacement sur la situation. Dans cette analyse, les deux premiers axes représentent 56,7% des observations. Il est même à noté que l’axe 3 ne représentent que quelque peu moins que l’axe 2. Sur la première dimension, les individus ayant une activité physique sont représenté à droite, là ou sur la deuxième dimension, ils semblent avoir une répartition homogène de ces individus. Pourtant, c’est bien cette deuxième dimension qui permet de caractérisé les individus selon leur score de fertilité et donc d’avoir la capacité de instigué au mieux un individus fertile ou infertile. En promettant cette fertilité, on s’aperçoit tout de même que les individus fertile sont disposés en haut de la représentation graphique. La PCA n’a pas apporté de nouvelle observation mais à confirmer le score comme un représentant de la fertilité. L’analyse en bootstrap permet d’observe une normalité améliorer pour la l’activité de marche (p = 0,106), l’activité total (p = 0,283) et le temps assis (p = 0,601). La comparaison de moyenne issus de se bootstrap montrent une différence de moyenne significatif entre le groupe fertile et infertile pour l’activité physique intense et le temps assis. La régression logistique confirme la l’activité de marche comme étant une variable significativement influente dans l’augmentation des chances de fertilité. Le score quant a lui est bien corrélé de manière significative avec l’activité physique intense et total.
Partie IV : Classification des données
Faisabilité de l’analyse de clustering
On vérifie la faisabilité de l’analyse en clustering en calculant la statistique de Hopkings.
Si l’indice de Hopkins est proche de 1, ça indique une tendance au regroupement et donc une argument possitifs à une analyse en cluster. Ici un score supérieur à 0,8 introduit bien une tendance au regroupement.
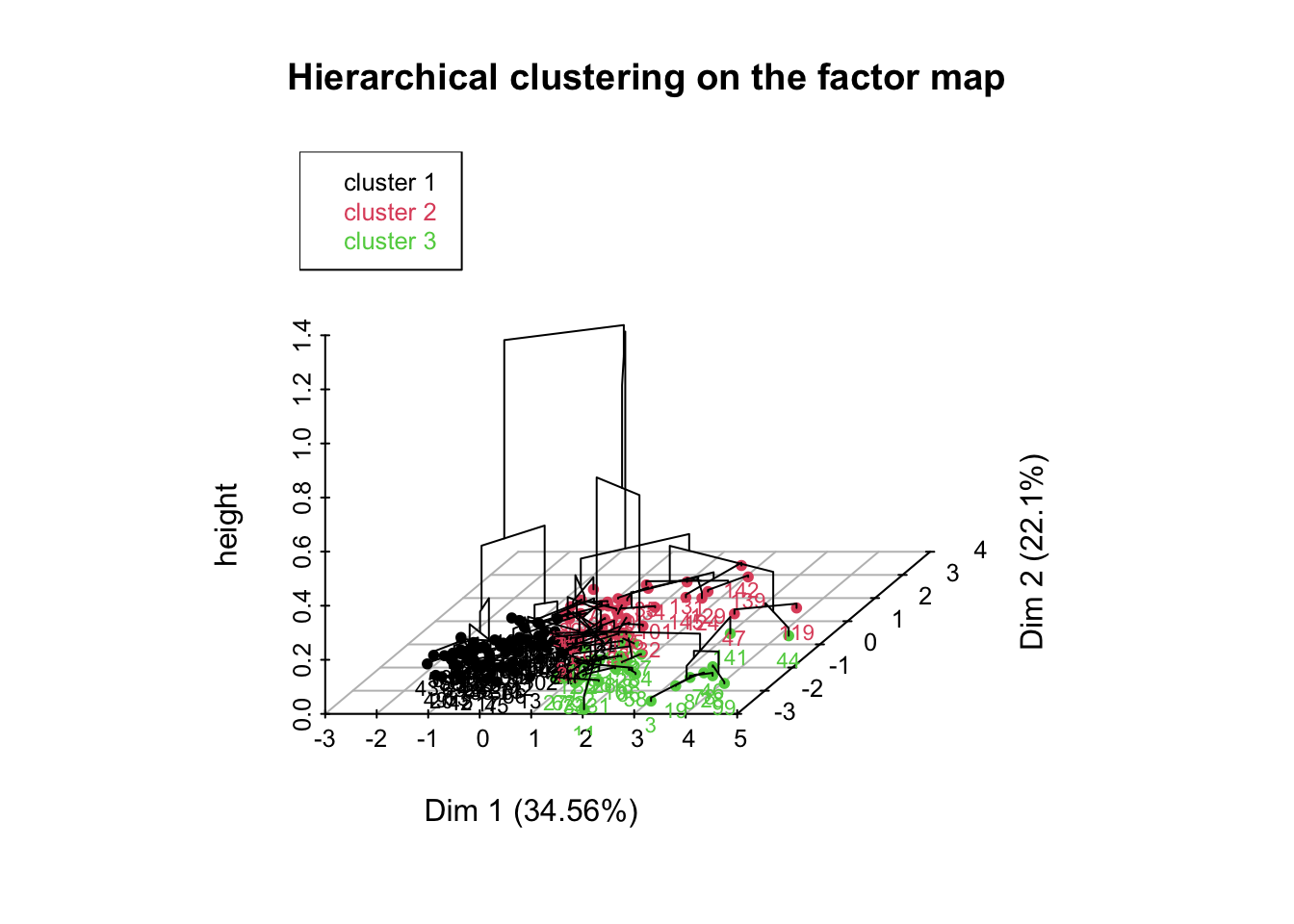
1. Détermination du nombre optimal de cluster
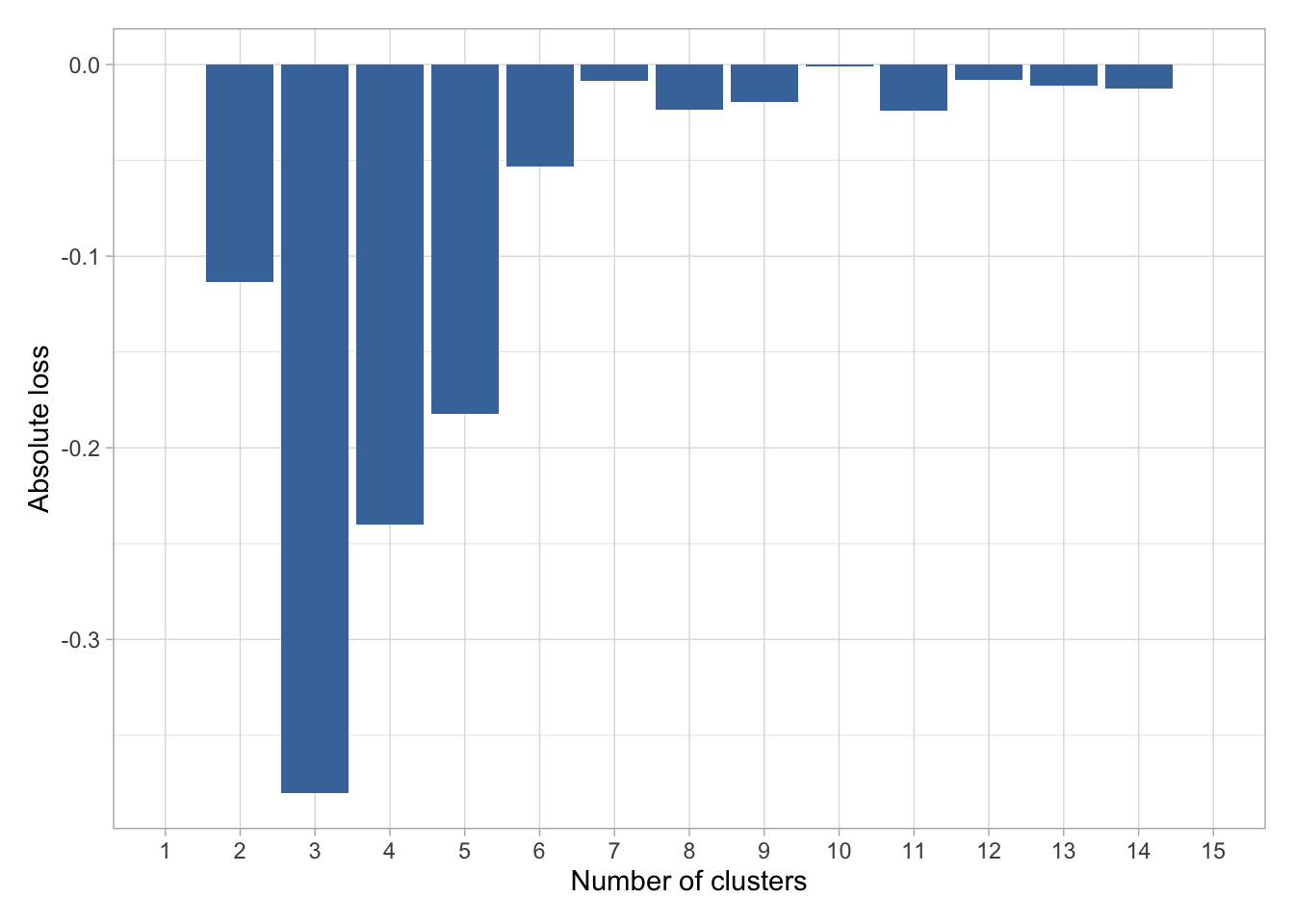
L’utilisation optimal de FactoMineR obligent à utiliser la partition ayant la plus grande perte relative d’inertie. On peut calculer cette indicateur via best.cutree. L’extension JLutils en propose une, la fonction regarde quelle serait la meilleure partition entre 3 et 20 classes
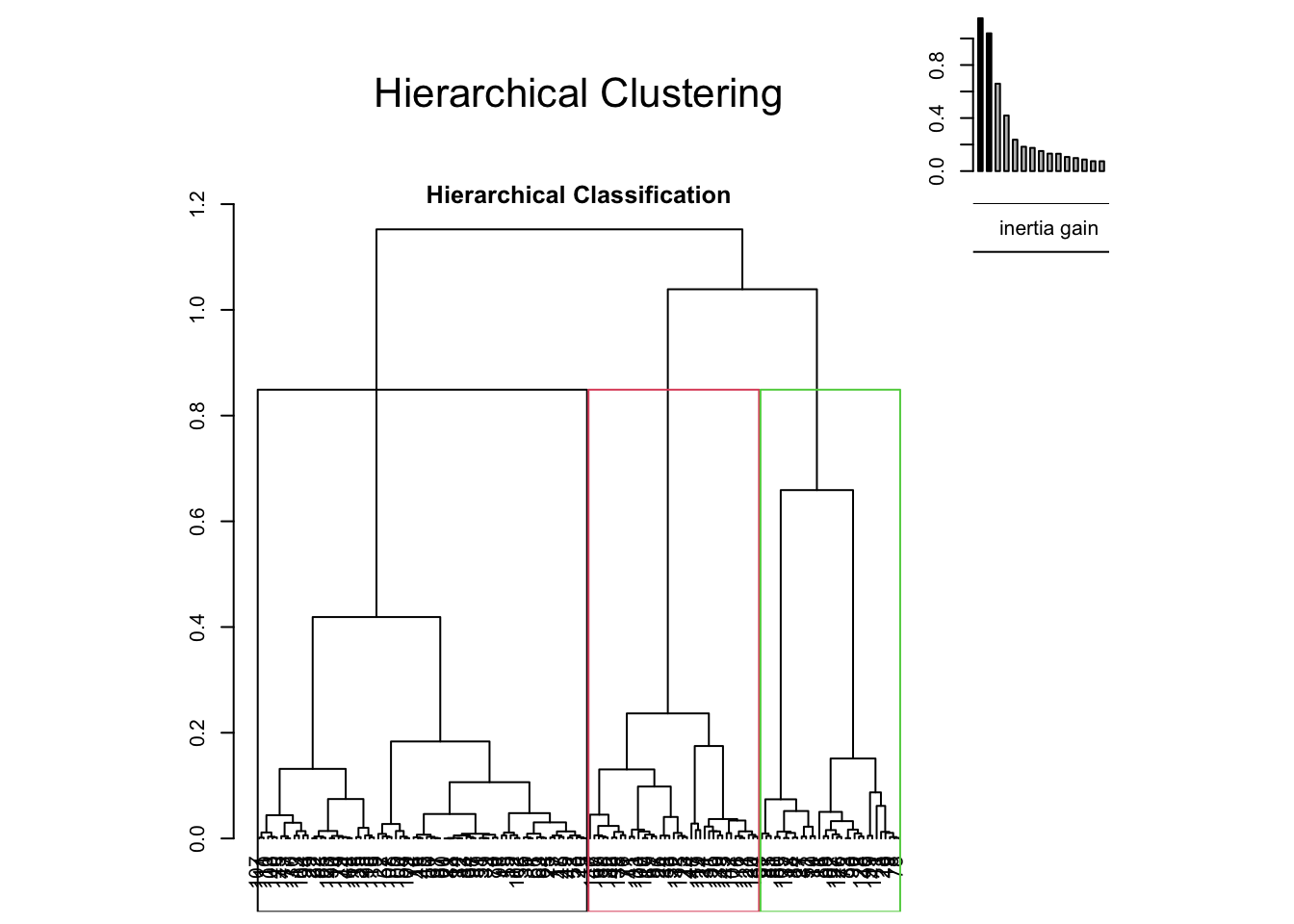
hc <-hclust(dist(d1), method="average")src<-source(url("https://raw.githubusercontent.com/larmarange/JLutils/master/R/clustering.R"))best<-best.cutree(hc)best
[1] 3
Le nombre idéal de Cluster serait de 4.
Pour confirmer ce choix, nous pouvons utiliser une pour observer les pertes absolue.
cah_fm <- FactoMineR::HCPC(res.pca, graph =FALSE, min =3)cah_fm |>plot_inertia_from_tree()
On remarque que la perte absolue est quasiment équivalente entre un nombre de cluster de 3 ou 4 (si on exclus le fait d’avoir que 2 clusters).
# Supposons que vos données s'appellent 'data'# Standardisation des variables d'activité physiquedata_standardized <- d1 %>%mutate(TempsAssis_z =scale(TempsAssis), # Standardisation du TempsAssisMarcheMET_z =scale(MarcheMET), # Standardisation du MarcheMETModereeMET_z =scale(ModéréeMET), # Standardisation du ModéréeMETIntensiteMET_z =scale(IntensitéMET) # Standardisation du IntensitéMET )# Inversion de la variable TempsAssis_z car elle diminue le scoredata_standardized <- data_standardized %>%mutate(TempsAssis_inv =-TempsAssis_z)# Création du score de sportivitédata_standardized <- data_standardized %>%mutate(Score_Sportivite = MarcheMET_z + ModereeMET_z + IntensiteMET_z )# Calcul de la moyenne des scores par groupescore_par_groupe <- data_standardized %>%group_by(typo_cah_fm) %>%summarise(Moyenne_Score =mean(Score_Sportivite, na.rm =TRUE))# Affichage du score par groupeprint(score_par_groupe)
d1 <- d1 %>%mutate(TempsAssis_z =scale(TempsAssis), # Standardisation du TempsAssisMarcheMET_z =scale(MarcheMET), # Standardisation du MarcheMETModereeMET_z =scale(ModéréeMET), # Standardisation du ModéréeMETIntensiteMET_z =scale(IntensitéMET), # Standardisation du IntensitéMETTempsAssis_inv =-TempsAssis_z, # Inversion du TempsAssis standardiséScore_Sportivite = TempsAssis_inv + MarcheMET_z + ModereeMET_z + IntensiteMET_z # Calcul du score )# Suppression des colonnes intermédiaires (si elles ne sont plus nécessaires)d1 <- d1 %>%select(-TempsAssis_z, -MarcheMET_z, -ModereeMET_z, -IntensiteMET_z, -TempsAssis_inv)
Characteristic
1, N = 791
2, N = 341
3, N = 331
Score.fertilité
0.46 (0.36, 0.55)
0.57 (0.47, 0.66)
0.45 (0.36, 0.53)
TempsAssis
327 (240, 420)
300 (240, 420)
240 (180, 300)
MarcheMET
330 (171, 495)
336 (264, 495)
660 (330, 1,980)
ModéréeMET
400 (0, 1,200)
1,200 (525, 2,400)
4,800 (3,600, 7,200)
IntensitéMET
0 (0, 0)
2,400 (2,400, 2,700)
0 (0, 0)
TotalMET
1,200 (495, 1,980)
4,048 (3,233, 5,183)
5,295 (4,380, 7,980)
Fertile
Non
48 (61%)
9 (26%)
16 (48%)
Oui
31 (39%)
25 (74%)
17 (52%)
Score_Sportivite
-1.45 (-2.28, -0.36)
0.98 (-0.02, 1.69)
2.14 (0.95, 2.82)
1 Median (IQR); n (%)
Tout comme chez l’homme, on retrouve un cluster qui montre un score de fertilité particulièrement élevé au 2 autres. Concernant les temps d’activité physique, ils sont en adéquation avec la sédentarité. On observe toute une fois une infertilité plus marqué pour le cluster 1 par rapport au cluster 3. Ce qui suppose une meilleurs classification que chez l’homme.
Test de l’indépendance des cluster
On créer des subset des cluster via les jeu de donnée d1
Hypothèse H0 : les clusters selon le score de fertilité suivent une distribution de loi normal
Voir le code
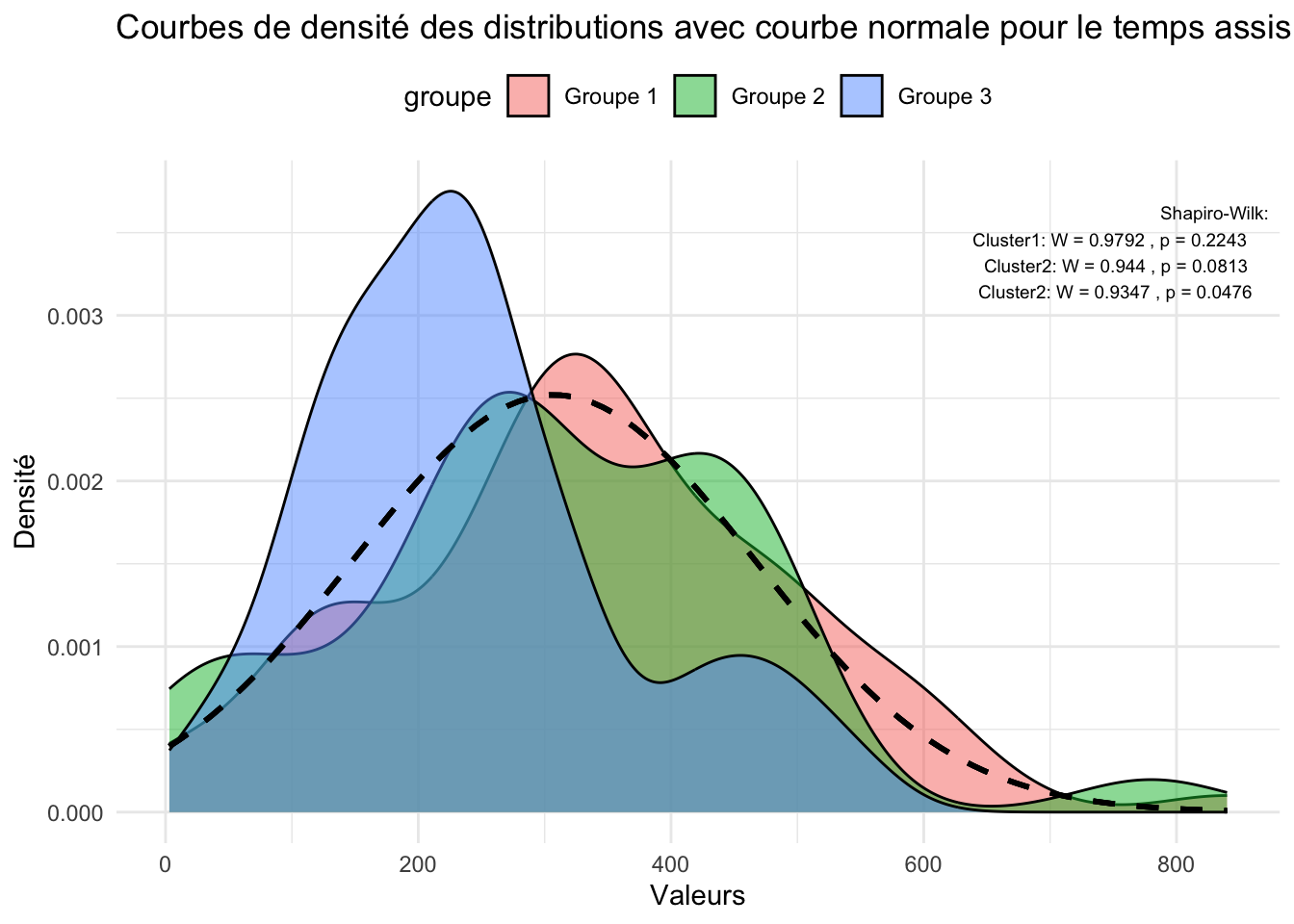
#Test de Shapiroshapiro_Cluster1=shapiro.test(Cluster1$Score.fertilité)shapiro_Cluster2=shapiro.test(Cluster2$Score.fertilité)shapiro_Cluster3=shapiro.test(Cluster3$Score.fertilité)shapiro_Cluster1a=shapiro.test(Cluster1$TempsAssis)shapiro_Cluster1b=shapiro.test(Cluster2$TempsAssis)shapiro_Cluster1c=shapiro.test(Cluster3$TempsAssis)#Réorganisation des data_framed3 <-data.frame(valeurs =c(Cluster1$Score.fertilité, Cluster2$Score.fertilité, Cluster3$Score.fertilité),groupe =factor(rep(c("Groupe 1", "Groupe 2", "Groupe 3"), times =c(length(Cluster1$Score.fertilité), length(Cluster2$Score.fertilité), length(Cluster3$Score.fertilité)))))d4 <-data.frame(valeurs =c(Cluster1$TempsAssis, Cluster2$TempsAssis, Cluster3$TempsAssis),groupe =factor(rep(c("Groupe 1", "Groupe 2", "Groupe 3"), times =c(length(Cluster1$TempsAssis), length(Cluster2$TempsAssis), length(Cluster3$TempsAssis)))))#Test ANOVAanova_resultat <-aov(valeurs ~ groupe, data = d3)anova_resultat2 <-aov(valeurs ~ groupe, data = d4)#Graphique pour le score de fertilitép4 <-ggplot(d3, aes(x = valeurs, fill = groupe)) +geom_density(alpha =0.5) +stat_function(fun = dnorm, args =list(mean =mean(d3$valeurs), sd =sd(d3$valeurs)), color ="black", size =1, linetype ="dashed") +# Courbe normalelabs(title ="Courbes de densité des distributions avec courbe normale pour le score", x ="Valeurs", y ="Densité") +theme_minimal() +theme(legend.position ="top")p4 <- p4 +annotate("text", x =Inf, y =Inf, label =paste("Shapiro-Wilk:\nCluster1: W =", round(shapiro_Cluster1$statistic, 4), ", p =", round(shapiro_Cluster1$p.value, 4), "\nCluster2: W =", round(shapiro_Cluster2$statistic, 4), ", p =", round(shapiro_Cluster2$p.value, 4),"\nCluster2: W =", round(shapiro_Cluster3$statistic, 4),", p =", round(shapiro_Cluster3$p.value, 4)),hjust =1.1, vjust =1.5, size =2.5, color ="black", parse =FALSE)#Graphique pour le temps assisp5 <-ggplot(d4, aes(x = valeurs, fill = groupe)) +geom_density(alpha =0.5) +stat_function(fun = dnorm, args =list(mean =mean(d4$valeurs), sd =sd(d4$valeurs)), color ="black", size =1, linetype ="dashed") +# Courbe normalelabs(title ="Courbes de densité des distributions avec courbe normale pour le temps assis", x ="Valeurs", y ="Densité") +theme_minimal() +theme(legend.position ="top")p5 <- p5 +annotate("text", x =Inf, y =Inf, label =paste("Shapiro-Wilk:\nCluster1: W =", round(shapiro_Cluster1a$statistic, 4), ", p =", round(shapiro_Cluster1a$p.value, 4), "\nCluster2: W =", round(shapiro_Cluster1b$statistic, 4), ", p =", round(shapiro_Cluster1b$p.value, 4),"\nCluster2: W =", round(shapiro_Cluster1c$statistic, 4),", p =", round(shapiro_Cluster1c$p.value, 4)),hjust =1.1, vjust =1.5, size =2.5, color ="black", parse =FALSE)
Faire l’interprêtation
Hypothèse H0 : Les moyennes des scores de fertilité et du temps assis des 3 groupes ne sont pas significativement différentes.
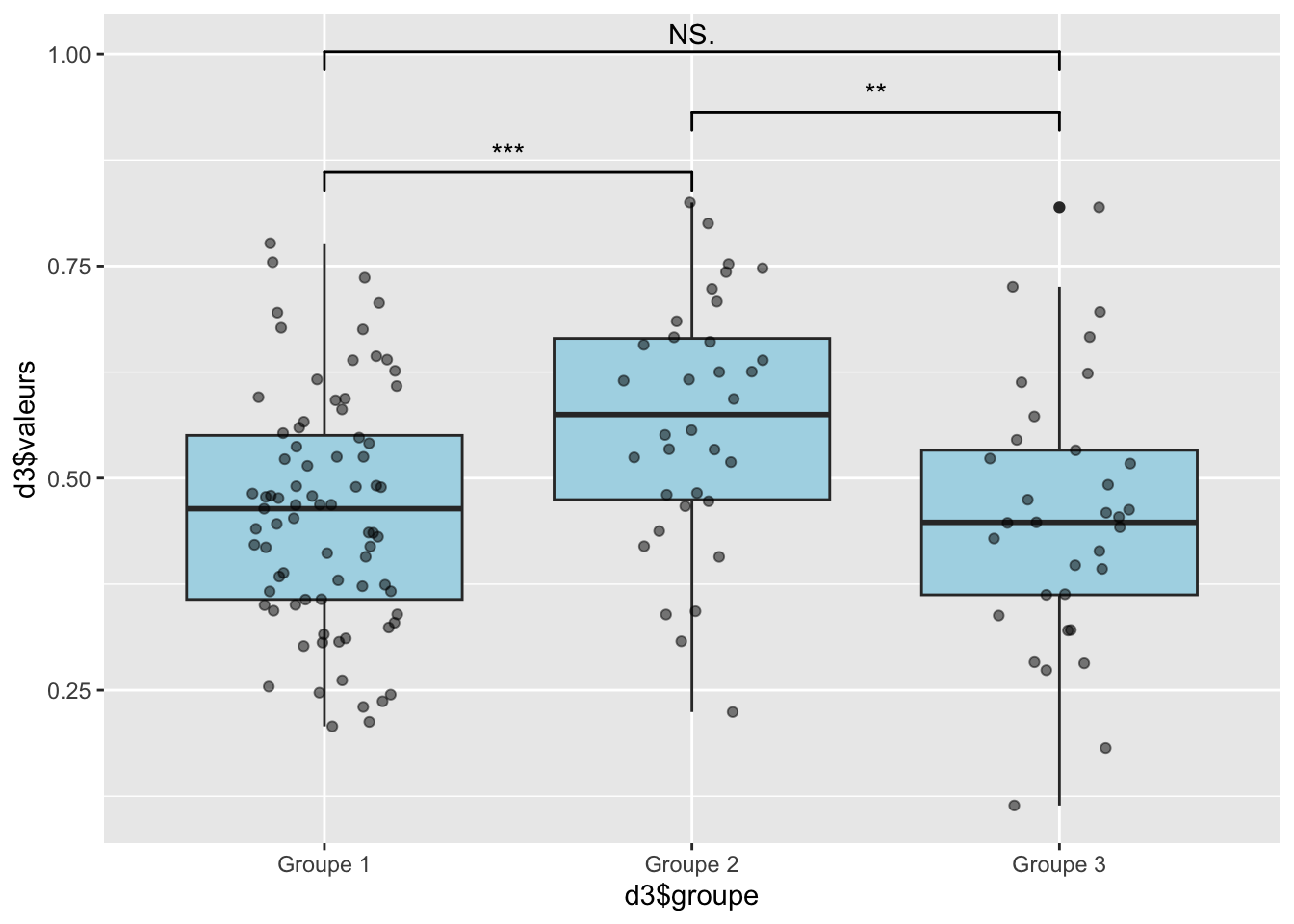
summary(anova_resultat)
Df Sum Sq Mean Sq F value Pr(>F)
groupe 2 0.311 0.15552 7.552 0.000762 ***
Residuals 143 2.945 0.02059
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
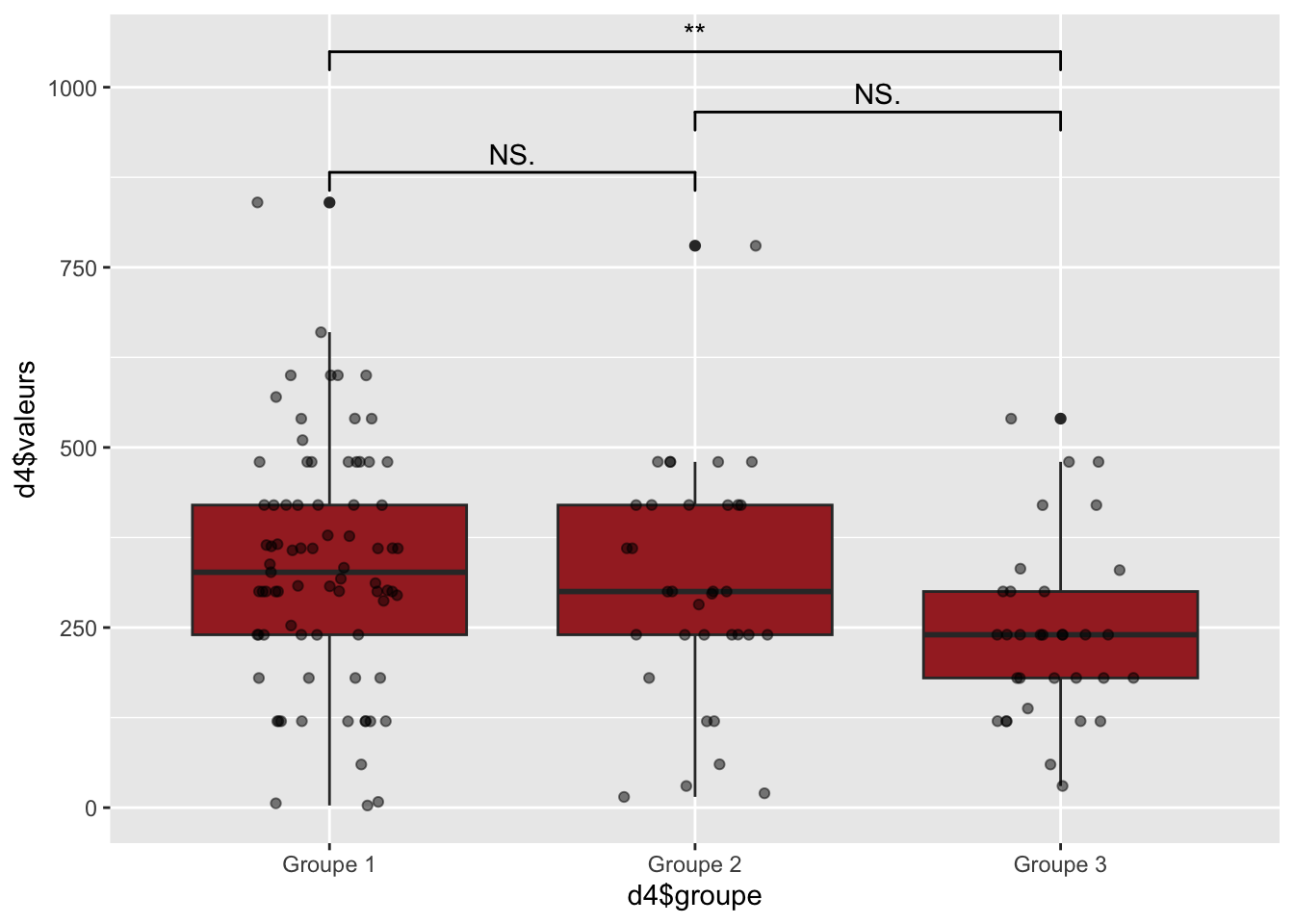
summary(anova_resultat2)
Df Sum Sq Mean Sq F value Pr(>F)
groupe 2 204456 102228 4.261 0.0159 *
Residuals 143 3430465 23989
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Résultat des ANOVA
On rejette l’hypothèse nul pour les 2 variables. Pour le score de fertilité et le temps assis, il y a une différence significative
Warning in wilcox.test.default(c(240, 780, 420, 360, 420, 480, 240, 480, :
cannot compute exact p-value with ties
interprêtation
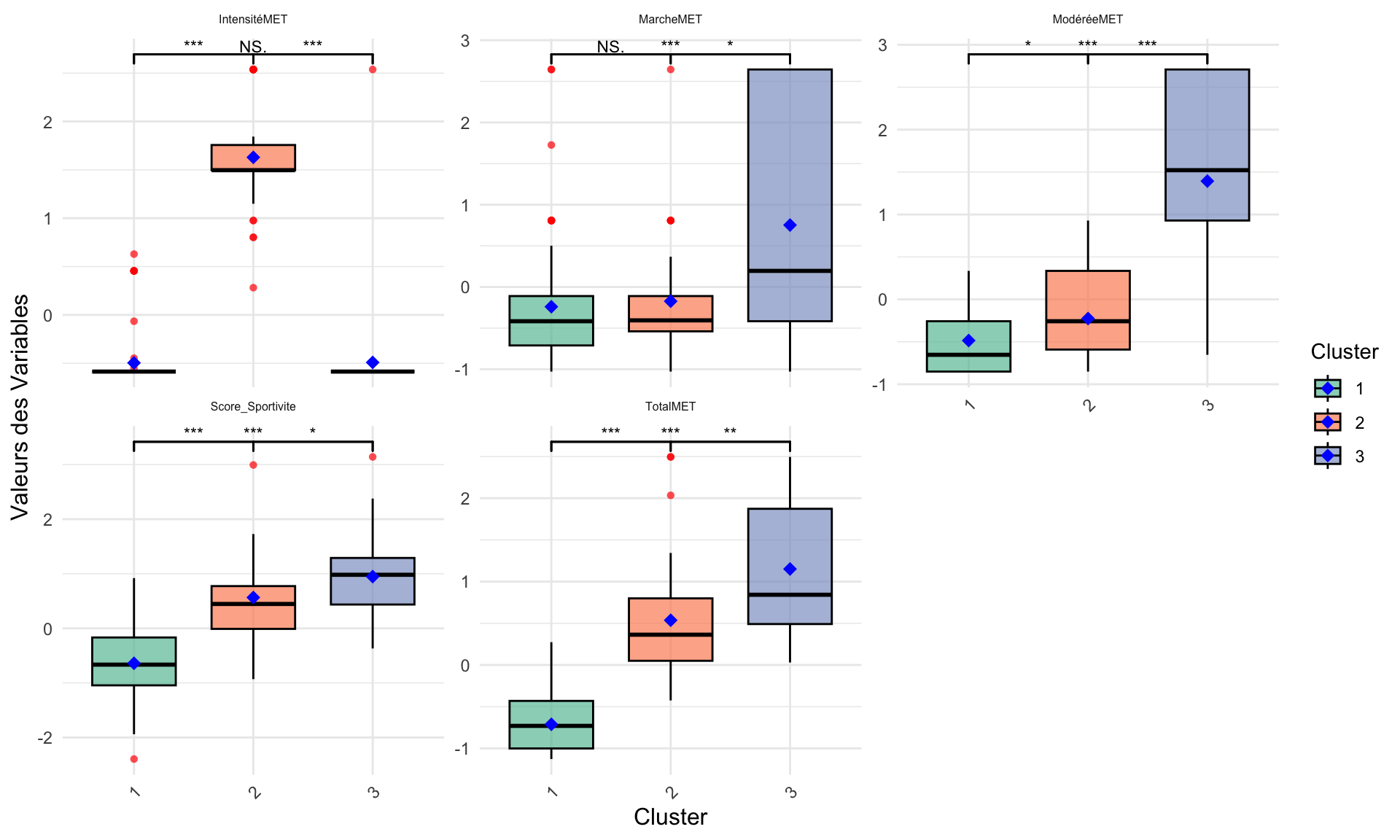
Analyse des autres variables par test non paramétrique
Hormis le score de fertilité et le temps assis, toutes les autres variables ne suivent pas une loi normal. Pour pouvoir tout de même ajuster le discours, on utilise la variante non paramétrique du test d’ANOVA : le test de Kurskall Wallis, le test de post HOC est le test de dunn.
Voir le code
d5=d1[,c(3,4,5,6,7,9)]names(d1)[names(d1) =="typo_cah_fm"] <-"Cluster"d1_normalized <- d1 %>%mutate(across(where(is.numeric), ~ (.-mean(.)) /sd(.)))d5_normalized <- d5 %>%mutate(across(where(is.numeric), ~ (.-mean(.)) /sd(.)))names(d5_normalized)[names(d5_normalized) =="typo_cah_fm"] <-"Cluster"# Convertir Cluster en facteurd5_normalized$Cluster <-as.factor(d5_normalized$Cluster)# Calculer les moyennes par clustermean_data <- d5_normalized %>%group_by(Cluster) %>%summarise(across(where(is.numeric), mean))# Tester la significativité des moyennes pour chaque variable avec Kruskal-Wallis et le test de Dunnanova_results <-lapply(names(mean_data)[-1], function(var) { formula <-as.formula(paste(var, "~ Cluster")) kw_result <-kruskal.test(formula, data = d5_normalized) tidy_result <-tidy(kw_result)# Si Kruskal-Wallis est significatif, faire un test de Dunnif (tidy_result$p.value[1] <0.05) { dunn_result <-dunn.test(d5_normalized[[var]], d5_normalized$Cluster, method ="bonferroni") dunn_df <-data.frame(comparison = dunn_result$comparisons,p_value = dunn_result$P.adjusted,Variable = var )return(dunn_df) } else {return(NULL) }})
Kruskal-Wallis rank sum test
data: x and group
Kruskal-Wallis chi-squared = 12.2768, df = 2, p-value = 0
Comparison of x by group
(Bonferroni)
Col Mean-|
Row Mean | 1 2
---------+----------------------
2 | -0.653002
| 0.7706
|
3 | -3.480742 -2.404260
| 0.0008* 0.0243*
alpha = 0.05
Reject Ho if p <= alpha/2
Kruskal-Wallis rank sum test
data: x and group
Kruskal-Wallis chi-squared = 60.6326, df = 2, p-value = 0
Comparison of x by group
(Bonferroni)
Col Mean-|
Row Mean | 1 2
---------+----------------------
2 | -2.051847
| 0.0603
|
3 | -7.781740 -4.878233
| 0.0000* 0.0000*
alpha = 0.05
Reject Ho if p <= alpha/2
Kruskal-Wallis rank sum test
data: x and group
Kruskal-Wallis chi-squared = 114.1407, df = 2, p-value = 0
Comparison of x by group
(Bonferroni)
Col Mean-|
Row Mean | 1 2
---------+----------------------
2 | -10.03402
| 0.0000*
|
3 | 0.514654 8.858631
| 0.9102 0.0000*
alpha = 0.05
Reject Ho if p <= alpha/2
Kruskal-Wallis rank sum test
data: x and group
Kruskal-Wallis chi-squared = 102.9078, df = 2, p-value = 0
Comparison of x by group
(Bonferroni)
Col Mean-|
Row Mean | 1 2
---------+----------------------
2 | -7.069079
| 0.0000*
|
3 | -9.050512 -1.743170
| 0.0000* 0.1220
alpha = 0.05
Reject Ho if p <= alpha/2
Kruskal-Wallis rank sum test
data: x and group
Kruskal-Wallis chi-squared = 79.2174, df = 2, p-value = 0
Comparison of x by group
(Bonferroni)
Col Mean-|
Row Mean | 1 2
---------+----------------------
2 | -6.356578
| 0.0000*
|
3 | -7.839968 -1.314429
| 0.0000* 0.2831
alpha = 0.05
Reject Ho if p <= alpha/2
# Combiner les résultats de Dunndunn_results_df <-bind_rows(anova_results)# Préparer les données pour le diagramme en boîted5_normalized_long <- d5_normalized %>%pivot_longer(cols =-Cluster, names_to ="Variable", values_to ="Valeur")
Warning in wilcox.test.default(c(1.4965995134689, 2.53791895254655,
1.4965995134689, : cannot compute exact p-value with ties
Warning in wilcox.test.default(c(-0.722429557975582, -1.02851443793905, :
cannot compute exact p-value with ties
Warning in wilcox.test.default(c(-0.257639395088843, -0.554290433598079, :
cannot compute exact p-value with ties
Warning in wilcox.test.default(c(0.254477974726414, 0.421506143728285,
0.841956362250236, : cannot compute exact p-value with ties
Faire l’interprêtation
4. Projection sur la fertilité
Pour finir l’analyse des clusters, on peut les projeters sur la fertilité pour comparer les groupes.
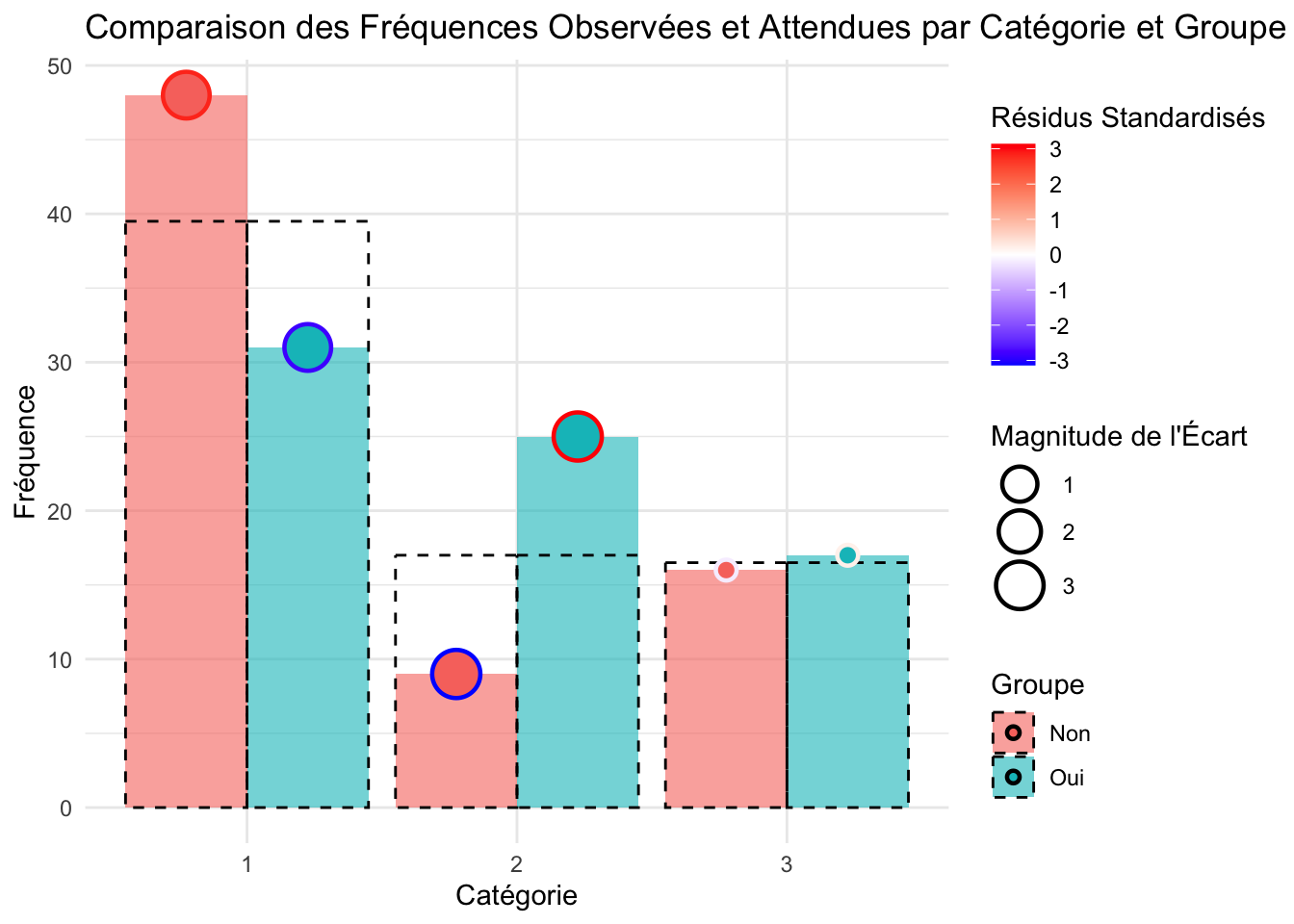
tabCont22 <-xtabs(~Fertile+d1$Cluster,data=d1)
Un test de Chi2 est réalisé
H0 : Il y a indépendance entre les variables qualitatives A et B.
X-squared
11.21794
5. Conclusion
Le score de Hopkins confirme la faisabilité d’une analyse en clustering. Selon l’extension JLutils, le nombre de cluster est idéalement de 3. La classification ascendante hiérarchique montre bien 3 clusters distincts qui ne semblent pas se chevaucher. Dans une première vu, le 2ème cluster possèdent un score plus élevé que les 2 autres groupes, ainsi qu’une score de sportivité plus faible que le groupe 3. Au vu de la normalité de distribution du score et du temps assis, on réalise un ANOVA. Le score de fertilité est bien significativeement différent pour le groupe 2 par rapport au deux autres groupes qui ne possèdent entre eux par de différence dans leur score. Le score de sportivité est significativement différent entre les trois groupes avec le 3ème groupe en tête, on observe intrinsèquement qu’il dispose de valeur plus élevé pour les activités de marche et d’activité physique modérée. Le groupe 2 quant a lui à une meilleurs activité physique intense mais qui ne permet pas, sur une mesure de l’activité physique totale, de rattraper le groupe 3 qui en plus de sa, se distingue par des individus moins sédentaire. On remarque là peut être un effet plus important de la marche et de la sédentarité que de l’activité physique sur une analyse total d’un profil de sportivité. La projection sur la fertilité montre que le groupe 2 comporte une proportion d’individus fertile plus importante, là ou le groupe 3 est à quasi égalité dans sa proposition. Avec un score de fertilité et de sportivité diminué, le groupe 1 à une plus grande proportion d’individus infertile.
Partie V : Apprentissage automatique
Parmis les différents, nous avons testé différent modèle de prédiction. Le modèle qui a retenu notre attention était le modèle de forêt aléatoire qui semblait présenter des meilleurs paramètres. Seulement, on peut se rendre compte que l’accurency et le Kappa varie beaucoup lors de la validation croisée. Ce qui justifie que nos données acutelles ne permettent pas de créer un bon modèle de prédiction.
Une application Shiny montre la variation des paramètres selon l’actualisation du graphique